numpy.random.RandomState.power#
方法
- random.RandomState.power(a, size=None)#
从指数为 a - 1 的幂分布中抽取 [0, 1] 区间的样本。
也称为幂函数分布。
- 参数:
- afloat 或 float 的数组类
分布的参数。必须为非负数。
- sizeint 或 int 的元组,可选
输出形状。如果给定的形状例如是
(m, n, k),则抽取m * n * k个样本。如果 size 为None(默认值),则当a是标量时,返回单个值。否则,抽取np.array(a).size个样本。
- 返回:
- outndarray 或标量
从参数化的幂函数分布中抽取样本。
- 引发:
- ValueError
如果 a <= 0。
另请参阅
random.Generator.power新代码应使用此方法。
备注
概率密度函数为
\[P(x; a) = ax^{a-1}, 0 \le x \le 1, a>0.\]幂函数分布是帕累托分布的倒数。它也可以看作是 Beta 分布的特例。
例如,它用于模拟保险索赔的过度报告。
参考
[1]Christian Kleiber, Samuel Kotz, “Statistical size distributions in economics and actuarial sciences”, Wiley, 2003。
[2]Heckert, N. A. and Filliben, James J. “NIST Handbook 148: Dataplot Reference Manual, Volume 2: Let Subcommands and Library Functions”, National Institute of Standards and Technology Handbook Series, June 2003. https://www.itl.nist.gov/div898/software/dataplot/refman2/auxillar/powpdf.pdf
示例
从分布中绘制样本
>>> a = 5. # shape >>> samples = 1000 >>> s = np.random.power(a, samples)
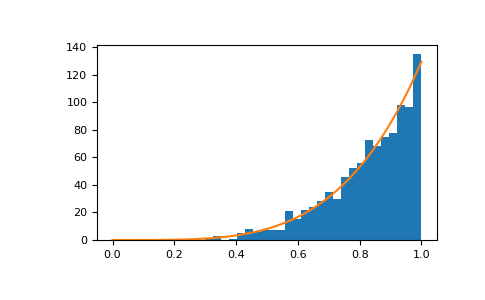
显示样本的直方图以及概率密度函数
>>> import matplotlib.pyplot as plt >>> count, bins, ignored = plt.hist(s, bins=30) >>> x = np.linspace(0, 1, 100) >>> y = a*x**(a-1.) >>> normed_y = samples*np.diff(bins)[0]*y >>> plt.plot(x, normed_y) >>> plt.show()
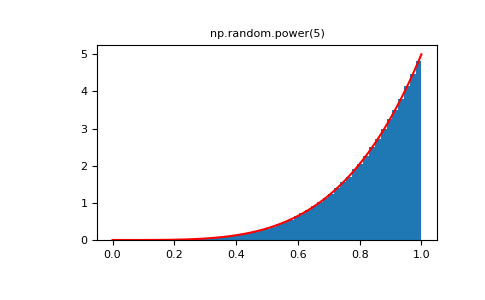
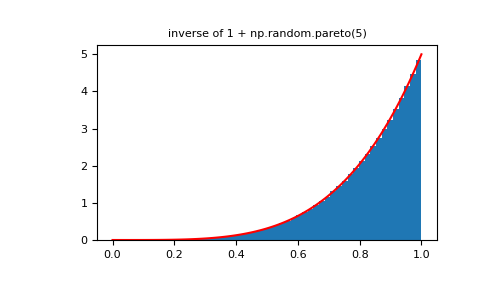
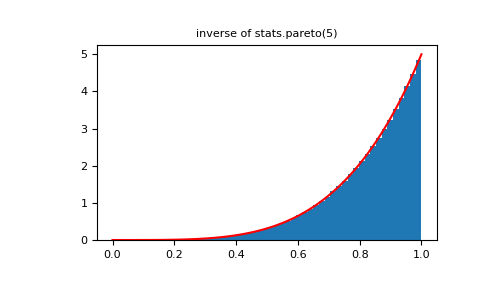
将幂函数分布与帕累托分布的倒数进行比较。
>>> from scipy import stats >>> rvs = np.random.power(5, 1000000) >>> rvsp = np.random.pareto(5, 1000000) >>> xx = np.linspace(0,1,100) >>> powpdf = stats.powerlaw.pdf(xx,5)
>>> plt.figure() >>> plt.hist(rvs, bins=50, density=True) >>> plt.plot(xx,powpdf,'r-') >>> plt.title('np.random.power(5)')
>>> plt.figure() >>> plt.hist(1./(1.+rvsp), bins=50, density=True) >>> plt.plot(xx,powpdf,'r-') >>> plt.title('inverse of 1 + np.random.pareto(5)')
>>> plt.figure() >>> plt.hist(1./(1.+rvsp), bins=50, density=True) >>> plt.plot(xx,powpdf,'r-') >>> plt.title('inverse of stats.pareto(5)')