numpy.random.Generator.binomial#
方法
- random.Generator.binomial(n, p, size=None)#
从二项分布中抽取样本。
从具有指定参数的二项分布中抽取样本,n 为试验次数,p 为成功概率,其中 n 是一个整数 >= 0,p 属于区间 [0,1]。 (n 可以作为浮点数输入,但在使用时会被截断为整数)
- 参数:
- n整数或类数组的整数
分布的参数,>= 0。也接受浮点数,但它们将被截断为整数。
- p浮点数或类数组的浮点数
分布的参数,>= 0 且 <= 1。
- sizeint 或 int 的元组,可选
输出形状。如果给定的形状是,例如,
(m, n, k),则抽取m * n * k个样本。如果 size 为None(默认),当n和p都是标量时,将返回单个值。否则,将抽取np.broadcast(n, p).size个样本。
- 返回:
- outndarray 或标量
从参数化的二项分布中抽取的样本,其中每个样本等于 n 次试验中成功的次数。
另请参阅
scipy.stats.binom概率密度函数、分布或累积密度函数等。
备注
二项分布的概率质量函数 (PMF) 是
\[P(N) = \binom{n}{N}p^N(1-p)^{n-N},\]其中 \(n\) 是试验次数,\(p\) 是成功概率,\(N\) 是成功次数。
当通过随机样本估计总体比例的标准误差时,除非 p*n <=5 (其中 p = 总体比例估计,n = 样本数量),否则正态分布效果很好,在这种情况下,则使用二项分布。例如,一个包含 15 人的样本显示 4 人是左撇子,11 人是右撇子。那么 p = 4/15 = 27%。 0.27*15 = 4,所以在这种情况下应该使用二项分布。
参考
[1]Dalgaard, Peter,“Introductory Statistics with R”,Springer-Verlag, 2002。
[2]Glantz, Stanton A.,“Primer of Biostatistics.”,McGraw-Hill,第五版,2002。
[3]Lentner, Marvin,“Elementary Applied Statistics”,Bogden and Quigley, 1972。
[4]Weisstein, Eric W. “Binomial Distribution.”, MathWorld–A Wolfram Web Resource. https://mathworld.net.cn/BinomialDistribution.html
[5]Wikipedia,“Binomial distribution”,https://en.wikipedia.org/wiki/Binomial_distribution
示例
从分布中绘制样本
>>> rng = np.random.default_rng() >>> n, p, size = 10, .5, 10000 >>> s = rng.binomial(n, p, 10000)
假设一家公司钻探了 9 口野猫式石油勘探井,每口井的成功概率估计为
p=0.1。所有九口井都失败了。这种情况发生的概率是多少?在
size = 20,000次试验中,这种情况发生的平均概率为>>> n, p, size = 9, 0.1, 20000 >>> np.sum(rng.binomial(n=n, p=p, size=size) == 0)/size 0.39015 # may vary
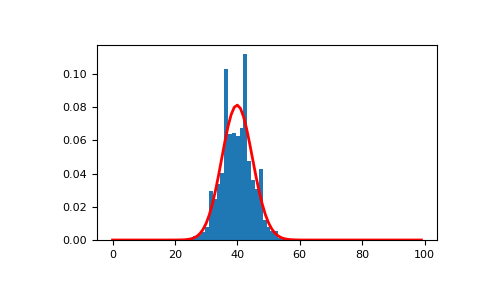
可以使用以下方法来可视化具有
n=100、p=0.4的样本及其相应的概率密度函数>>> import matplotlib.pyplot as plt >>> from scipy.stats import binom >>> n, p, size = 100, 0.4, 10000 >>> sample = rng.binomial(n, p, size=size) >>> count, bins, _ = plt.hist(sample, 30, density=True) >>> x = np.arange(n) >>> y = binom.pmf(x, n, p) >>> plt.plot(x, y, linewidth=2, color='r')