
n维数组上的线性代数#
先决条件#
在阅读本教程之前,您应该了解一些Python知识。如果您想温习一下,请查看Python教程。
如果您想运行本教程中的示例,您的计算机上还应该安装有matplotlib和SciPy。
学习者概况#
本教程适用于对线性代数和NumPy数组有基本理解,并希望了解n维(\(n>=2\))数组如何表示和操作的人。特别是,如果您不知道如何(不使用for循环)将常用函数应用于n维数组,或者如果您想了解n维数组的轴和形状属性,本教程可能会有所帮助。
学习目标#
完成本教程后,您应该能够
理解NumPy中一维、二维和n维数组之间的区别;
理解如何在不使用for循环的情况下,将一些线性代数运算应用于n维数组;
理解n维数组的轴和形状属性。
内容#
在本教程中,我们将使用线性代数中的矩阵分解(奇异值分解),来生成图像的压缩近似。我们将使用来自scipy.datasets模块的face图像。
# TODO: Rm try-except with scipy 1.10 is the minimum supported version
try:
from scipy.datasets import face
except ImportError: # Data was in scipy.misc prior to scipy v1.10
from scipy.misc import face
img = face()
Downloading file 'face.dat' from 'https://raw.githubusercontent.com/scipy/dataset-face/main/face.dat' to '/home/circleci/.cache/scipy-data'.
**注意**:如果您愿意,可以在学习本教程时使用自己的图像。要将图像转换为可操作的NumPy数组,您可以使用matplotlib.pyplot子模块中的imread函数。或者,您可以使用imageio库中的imageio.imread函数。请注意,如果您使用自己的图像,可能需要调整以下步骤。有关图像转换为NumPy数组后如何处理的更多信息,请参阅scikit-image文档中的图像的NumPy速成课程。
现在,img是一个NumPy数组,我们可以通过使用type函数来验证。
type(img)
numpy.ndarray
我们可以使用matplotlib.pyplot.imshow函数和特殊的iPython命令%matplotlib inline来内联显示图像。
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(img)
plt.show()

形状、轴和数组属性#
请注意,在线性代数中,向量的维度指的是数组中条目的数量。而在NumPy中,它定义的是轴的数量。例如,一维数组是像[1, 2, 3]这样的向量,二维数组是矩阵,依此类推。
首先,让我们检查数组中数据的形状。由于此图像是二维的(图像中的像素形成一个矩形),我们可能期望用一个二维数组(一个矩阵)来表示它。然而,使用此NumPy数组的shape属性会得到不同的结果。
img.shape
(768, 1024, 3)
输出是一个包含三个元素的元组,这意味着这是一个三维数组。实际上,由于这是一个彩色图像,并且我们使用了imread函数来读取它,因此数据组织成三个二维数组,表示颜色通道(此处为红色、绿色和蓝色 - RGB)。通过查看上面的形状可以发现这一点:它表明我们有一个包含3个矩阵的数组,每个矩阵的形状均为768x1024。
此外,使用此数组的ndim属性,我们可以看到
img.ndim
3
NumPy将每个维度称为一个*轴*。由于imread的工作方式,*第三轴中的第一个索引*是图像的红色像素数据。我们可以通过以下语法访问它。
img[:, :, 0]
array([[121, 138, 153, ..., 119, 131, 139],
[ 89, 110, 130, ..., 118, 134, 146],
[ 73, 94, 115, ..., 117, 133, 144],
...,
[ 87, 94, 107, ..., 120, 119, 119],
[ 85, 95, 112, ..., 121, 120, 120],
[ 85, 97, 111, ..., 120, 119, 118]],
shape=(768, 1024), dtype=uint8)
从上面的输出中,我们可以看到img[:, :, 0]中的每个值都是0到255之间的整数值,表示每个相应图像像素的红色水平(请记住,如果您使用自己的图像而不是scipy.datasets.face,这可能会有所不同)。
如预期,这是一个768x1024的矩阵。
img[:, :, 0].shape
(768, 1024)
由于我们将在这些数据上执行线性代数运算,因此将矩阵的每个条目中的RGB值表示为0到1之间的实数可能会更有趣。我们可以通过设置来做到这一点。
img_array = img / 255
此操作(用标量除以数组)之所以有效,是因为NumPy的广播规则。(请注意,在实际应用中,最好使用例如scikit-image中的img_as_float实用函数)。
您可以通过进行一些测试来验证上述操作是否有效;例如,查询此数组的最大值和最小值。
img_array.max(), img_array.min()
(np.float64(1.0), np.float64(0.0))
或检查数组中的数据类型。
img_array.dtype
dtype('float64')
请注意,我们可以使用切片语法将每个颜色通道分配给一个单独的矩阵。
red_array = img_array[:, :, 0]
green_array = img_array[:, :, 1]
blue_array = img_array[:, :, 2]
轴上的操作#
可以使用线性代数方法来近似现有数据集。在这里,我们将使用SVD(奇异值分解)来尝试重建一个使用比原始图像更少奇异值信息,但仍保留其某些特征的图像。
**注意**:我们将使用NumPy的线性代数模块numpy.linalg来执行本教程中的操作。此模块中的大多数线性代数函数也可以在scipy.linalg中找到,并且鼓励用户在实际应用中使用scipy模块。但是,scipy.linalg模块中的某些函数(例如SVD函数)仅支持二维数组。有关此内容的更多信息,请查看scipy.linalg页面。
要继续,请从NumPy导入线性代数子模块。
from numpy import linalg
为了从给定矩阵中提取信息,我们可以使用SVD来获得3个数组,这些数组相乘后可以得到原始矩阵。根据线性代数理论,给定一个矩阵\(A\),可以计算以下乘积:
其中\(U\)和\(V^T\)是方阵,而\(\Sigma\)的大小与\(A\)相同。\(\Sigma\)是一个对角矩阵,包含\(A\)的奇异值,并按从大到小的顺序排列。这些值始终是非负的,可以作为矩阵\(A\)所代表的某些特征“重要性”的指标。
让我们首先看看这在单个矩阵中是如何实际操作的。请注意,根据色度学,如果我们应用以下公式,可以获得一个相当合理的彩色图像灰度版本:
其中\(Y\)是代表灰度图像的数组,而\(R\)、\(G\)和\(B\)是我们最初的红色、绿色和蓝色通道数组。请注意,我们可以使用@运算符(NumPy数组的矩阵乘法运算符,参见numpy.matmul)来实现这一点。
img_gray = img_array @ [0.2126, 0.7152, 0.0722]
现在,img_gray的形状为
img_gray.shape
(768, 1024)
为了查看这在图像中是否有意义,我们应该使用matplotlib中与我们希望在图像中看到的颜色相对应的色彩图(否则,matplotlib将默认使用与真实数据不符的色彩图)。
在我们的例子中,我们正在近似图像的灰度部分,因此我们将使用色彩图gray。
plt.imshow(img_gray, cmap="gray")
plt.show()

现在,将linalg.svd函数应用于此矩阵,我们获得以下分解:
U, s, Vt = linalg.svd(img_gray)
**注意**:如果您使用的是自己的图像,此命令可能需要一些时间才能运行,具体取决于您的图像大小和硬件。别担心,这是正常的!SVD可能是一个相当密集的计算。
让我们检查这是否符合预期。
U.shape, s.shape, Vt.shape
((768, 768), (768,), (1024, 1024))
请注意,s具有特殊的形状:它只有一个维度。这意味着某些期望二维数组的线性代数函数可能无法工作。例如,从理论上讲,人们可能期望s和Vt兼容乘法。然而,事实并非如此,因为s没有第二个轴。执行
s @ Vt
会导致ValueError。出现这种情况是因为,在这种情况下,使用s的一维数组在实践中比使用相同数据构建对角矩阵经济得多。为了重建原始矩阵,我们可以使用s的元素在其对角线上,并使用适合乘法的适当维度来重建对角矩阵\(\Sigma\):在我们的例子中,\(\Sigma\)应为768x1024,因为U是768x768,Vt是1024x1024。为了将奇异值添加到Sigma的对角线中,我们将使用NumPy的fill_diagonal函数。
import numpy as np
Sigma = np.zeros((U.shape[1], Vt.shape[0]))
np.fill_diagonal(Sigma, s)
现在,我们想检查重建的U @ Sigma @ Vt是否接近原始的img_gray矩阵。
近似#
linalg模块包含一个norm函数,用于计算NumPy数组中表示的向量或矩阵的范数。例如,根据上述SVD解释,我们期望img_gray与重建的SVD乘积之间的差值的范数很小。如预期,您应该看到类似以下内容:
linalg.norm(img_gray - U @ Sigma @ Vt)
np.float64(1.436745484142884e-12)
(此操作的实际结果可能因您的架构和线性代数设置而异。无论如何,您都应该看到一个小数。)
我们也可以使用numpy.allclose函数来确保重建的乘积实际上*接近*我们的原始矩阵(即两个数组之间的差异很小)。
np.allclose(img_gray, U @ Sigma @ Vt)
True
为了查看近似是否合理,我们可以检查s中的值。
plt.plot(s)
plt.show()
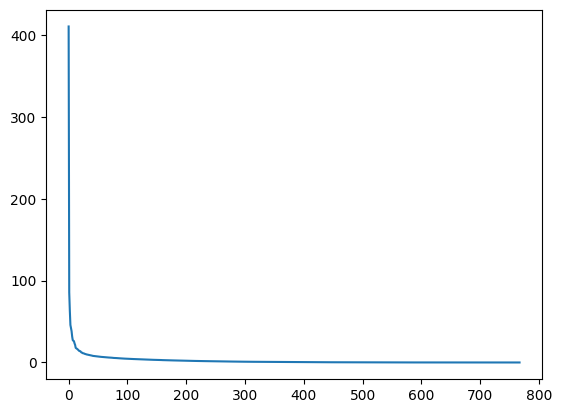
在图中,我们可以看到,尽管s中有768个奇异值,但其中大部分(大约在第150个条目之后)都相当小。因此,只使用与前(例如,50个)*奇异值*相关的信息来构建图像的更经济的近似可能是有意义的。
这个想法是,将Sigma中除了前k个奇异值(与s中的相同)之外的所有奇异值视为零,同时保持U和Vt不变,然后计算这些矩阵的乘积作为近似。
例如,如果我们选择
k = 10
我们可以通过以下方式构建近似:
approx = U @ Sigma[:, :k] @ Vt[:k, :]
请注意,我们必须只使用Vt的前k行,因为所有其他行都将乘以与我们在此近似中消除的奇异值相对应的零。
plt.imshow(approx, cmap="gray")
plt.show()

现在,您可以继续使用k的其他值重复此实验,您的每个实验都应该根据您选择的值,给出稍微更好(或更差)的图像。
应用于所有颜色#
现在我们想对所有三种颜色执行同样的操作。我们的第一直觉可能是将上述操作分别重复应用于每个颜色矩阵。然而,NumPy的*广播*为我们处理好了这一点。
如果我们的数组有超过两个维度,那么SVD可以一次性应用于所有轴。然而,NumPy中的线性代数函数期望看到形式为(n, M, N)的数组,其中第一个轴n代表堆栈中MxN矩阵的数量。
在我们的例子中,
img_array.shape
(768, 1024, 3)
所以我们需要对这个数组的轴进行置换,以获得类似(3, 768, 1024)的形状。幸运的是,numpy.transpose函数可以为我们做到这一点。
np.transpose(x, axes=(i, j, k))
表示轴将重新排序,使得转置数组的最终形状将根据索引(i, j, k)进行重新排序。
让我们看看这对于我们的数组是如何进行的。
img_array_transposed = np.transpose(img_array, (2, 0, 1))
img_array_transposed.shape
(3, 768, 1024)
现在我们准备好应用SVD了。
U, s, Vt = linalg.svd(img_array_transposed)
最后,为了获得完整的近似图像,我们需要将这些矩阵重新组合成近似结果。现在,请注意
U.shape, s.shape, Vt.shape
((3, 768, 768), (3, 768), (3, 1024, 1024))
为了构建最终的近似矩阵,我们必须了解跨不同轴的乘法是如何工作的。
与n维数组的乘积#
如果您之前只使用过NumPy中的一维或二维数组,您可能会互换使用numpy.dot和numpy.matmul(或@运算符)。然而,对于n维数组,它们的工作方式非常不同。有关更多详细信息,请查看numpy.matmul的文档。
现在,为了构建我们的近似,我们首先需要确保我们的奇异值已准备好进行乘法,因此我们像之前一样构建Sigma矩阵。Sigma数组必须具有(3, 768, 1024)的维度。为了将奇异值添加到Sigma的对角线中,我们将再次使用fill_diagonal函数,将s中的3行分别用作Sigma中3个矩阵的对角线。
Sigma = np.zeros((3, 768, 1024))
for j in range(3):
np.fill_diagonal(Sigma[j, :, :], s[j, :])
现在,如果我们希望重建完整的SVD(无近似),我们可以这样做:
reconstructed = U @ Sigma @ Vt
请注意
reconstructed.shape
(3, 768, 1024)
重建后的图像应该与原始图像无法区分,除了重建导致的浮点误差差异外。回想一下,我们的原始图像由范围[0., 1.]内的浮点值组成。重建过程中浮点误差的累积可能导致值略微超出此原始范围。
reconstructed.min(), reconstructed.max()
(np.float64(-7.431555371084642e-15), np.float64(1.000000000000005))
由于imshow期望范围内的值,我们可以使用clip来截除浮点误差。
reconstructed = np.clip(reconstructed, 0, 1)
plt.imshow(np.transpose(reconstructed, (1, 2, 0)))
plt.show()

实际上,imshow在底层执行此剪切操作,因此如果您跳过上一个代码单元格的第一行,您可能会看到警告消息,显示"Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers)."
现在,要进行近似,我们必须为每个颜色通道选择仅前k个奇异值。这可以使用以下语法完成:
approx_img = U @ Sigma[..., :k] @ Vt[..., :k, :]
您可以看到,我们只选择了Sigma的最后一个轴的前k个分量(这意味着我们只使用了堆栈中三个矩阵的每个矩阵的前k列),并且我们只选择了Vt的倒数第二个轴的前k个分量(这意味着我们从堆栈Vt中的每个矩阵中仅选择了前k行和所有列)。如果您不熟悉省略号语法,它是一个用于其他轴的占位符。有关更多详细信息,请参阅索引文档。
现在,
approx_img.shape
(3, 768, 1024)
这不是显示图像的正确形状。最后,将轴重新排序回我们原始的(768, 1024, 3)形状,我们可以看到我们的近似图像。
plt.imshow(np.transpose(approx_img, (1, 2, 0)))
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-0.13567131472460806..1.079453607915587].
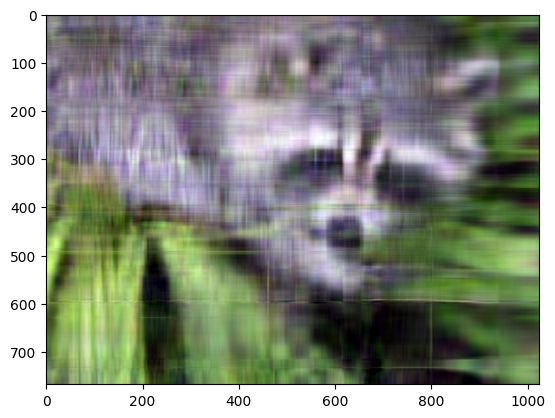
尽管图像不那么清晰,但使用少量k奇异值(与原始的768个值相比),我们仍然可以从该图像中恢复许多显著特征。
最后的话#
当然,这不是*近似*图像的最佳方法。然而,在线性代数中,确实有一个结果表明,我们上面构建的近似在差值范数方面是与原始矩阵最接近的。有关更多信息,请参阅*G. H. Golub and C. F. Van Loan, Matrix Computations, Baltimore, MD, Johns Hopkins University Press, 1985*。