优先级¶
fname = "data/2021/numpy_survey_results.tsv"
column_names = [
'website', 'performance', 'reliability', 'packaging', 'new_features',
'documentation', 'other'
]
priorities_dtype = np.dtype({
"names": column_names,
"formats": ['U1'] * len(column_names),
})
data = np.loadtxt(
fname, delimiter='\t', skiprows=3, dtype=priorities_dtype,
usecols=range(58, 65), comments=None, encoding='UTF-16'
)
# Discard empty data
num_respondents = data.shape[0]
unstructured = data.view(np.dtype('(7,)U1'))
data = data[~np.any(unstructured == '', axis=1)]
glue('2021_num_prioritizers', gluval(data.shape[0], num_respondents), display=False)
我们请受访者分享他们对 NumPy 的优先级,以了解 NumPy 社区的需求和愿望。用户被要求按优先级顺序对以下类别进行排名
for category in sorted(column_names[:-1]):
print(f" - {category.replace('_', ' ').capitalize()}")
- Documentation
- New features
- Packaging
- Performance
- Reliability
- Website
还包含一个自由填写类别(Other),以便参与者可以分享上述列表之外的优先级。
概述¶
在 522 名受访者中,有 362 名 (69%) 分享了他们对 NumPy 未来发展的优先级。
为了了解每个类别的总体相对“重要性”,下图总结了通过Borda 计数程序(用于排序选择投票)确定的每个类别的分数。
# Unstructured, numerical data
raw = data.view(np.dtype('U1')).reshape(-1, len(column_names)).astype(int)
borda = len(column_names) + 1 - raw
relative_score = np.sum(borda, axis=0)
relative_score = 100 * relative_score / relative_score.sum()
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
I = np.argsort(relative_score)
labels, relative_score = labels[I], relative_score[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(len(relative_score)), relative_score, tick_label=labels)
ax.set_xlabel('Relative Borda score (%)')
ax.set_title("Overall Importance Score");
fig.tight_layout()
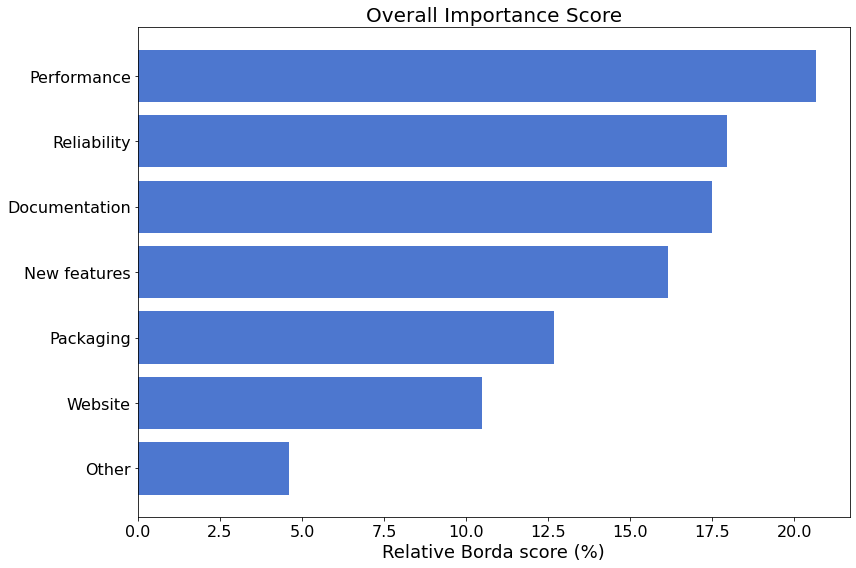
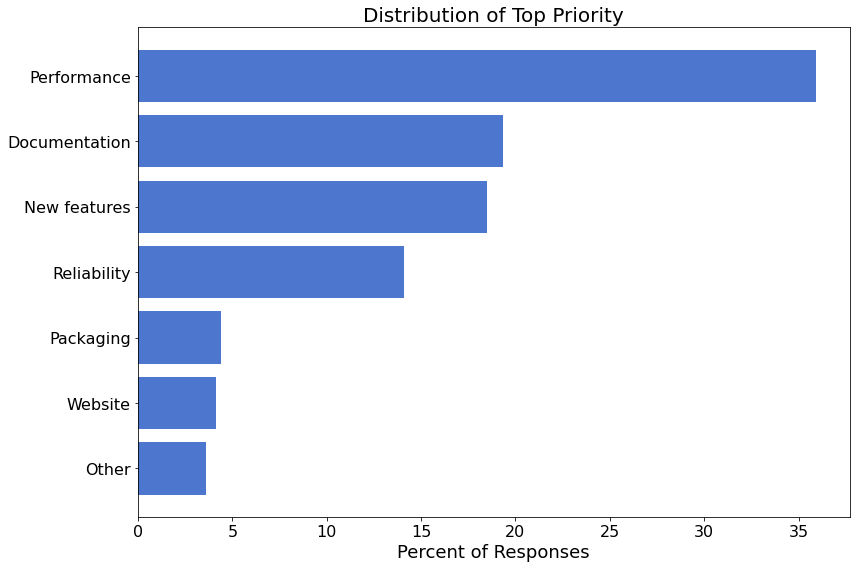
在首要优先级中,我们将更仔细地研究各项事物的优先级。
首要优先级¶
下图显示了首要优先级项目的细分情况。
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
# Collate top-priority data
cnts = np.sum(raw == 1, axis=0)
I = np.argsort(cnts)
labels, cnts = labels[I], cnts[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title('Distribution of Top Priority')
ax.set_xlabel('Percent of Responses')
fig.tight_layout()
详情¶
我们要求分享优先级的受访者详细说明他们的前两项优先级。例如,如果用户将“性能”列为首要优先级,则会要求他们分享关于如何改进性能的具体想法。每个类别的回复如下所示。
categories = {
"docs", "newfeatures", "other", "packaging", "performance", "reliability",
"website",
}
# Load the text responses for each category
response_dict = {}
for category in categories:
responses = np.loadtxt(
f"data/2021/{category}_comments_master.tsv", delimiter='\t', skiprows=1,
usecols=0, dtype='U', comments=None
)
responses = responses[responses != '']
response_dict[category] = responses
# Generate nicely-formatted lists
for category, responses in response_dict.items():
gen_mdlist(responses, f"{category}_comments_list.md")
# Register number of responses in each category
for k, v in response_dict.items():
glue(f"2021_num_{k}_comments", v.shape[0], display=False)
文档¶
有 69 名参与者分享了他们对如何改进文档的看法。
点击展开!
评论 |
|---|
最近我发现矩阵乘法类函数的文档不够详细 |
示例,到处都是示例! |
提供更多语言版本,在拉美地区,我们在研究领域,尤其是在大学里,大量使用 NumPy。创建社区活动,让人们可以提出新的做事方式。NumPy 不仅仅是一个库,它的潜力可以将研究与软件工程连接起来。 |
提供测试用例的文档会很好。除此之外,也许在你的文档中可以提供更多示例 |
更多示例,教程。我不熟悉许多算法的深层数学原理,但通常在阅读文档时觉得,除了编程知识外,还需要高水平的数学知识才能弄清楚给定方法应该如何用于哪种数据。 |
更多教程、操作指南、手册、示例 |
文档大部分都很清晰。欢迎提供更多方法的使用示例。我经常发现自己要去 StackOverflow 或类似页面查找使用示例,因为文档中提供的示例有时非常有限。 |
调查迫使我选择一些优先级顺序,因此我认为性能、可靠性和文档对我的工作来说是最重要的。根据我的经验,NumPy 速度快、可靠且文档清晰。” |
更高级、更复杂的示例。为没有数值数学/编程背景的人提供教程。 |
添加更多使用示例。提供一些“有上下文”的示例。例如,这些操作在特定上下文中如何或可以如何使用。 |
保持更新并添加大量示例 |
文档中指向教程和示例的链接展示了 NumPy 的强大功能。我在文档中看到了所有这些令人惊叹的函数,但作为新手,我不确定如何或为何使用它们。 |
更好的解释。特别是算法的解释,以及初学者与中级 NumPy 用户(例如步幅、批处理等)的难点。 |
使用结构化数组的示例 |
文档的某些部分已过时。 |
文档已经很好了!但如果能多一点关于即将发布的版本/弃用路线图的沟通就更好了。 |
有些文档对初学者来说有点简短,理解某些方法的用法需要一些时间,也许一个包含更简单描述和大量示例的“初学者模式”文档会有所帮助,但大多数时候我还是在 StackOverflow 上找到提示。 |
用例。(此评论以日文提交。) |
单个页面通常很好,但整体组织有时会让人困惑。 |
文档中应有更多示例。 |
示例和解释。何时更正确地使用某个功能而非另一个。如何使您的 NumPy 代码更快。如何管理内存或系统资源。如何使用 GPU 或并行化计算。 |
解释如何在计算中使用变量的单位。” |
清理文档结构和一致性 |
更具体的示例。提示和技巧。 |
更明确的文档,更详细且提供更多示例。(此评论以法文提交。) |
找不到所有函数及其参数工作方式的完整列表。dir() 函数会列出数百个函数。应该有一个 PDF 或网站,详细记录每个函数及其参数。还可以按功能对其进行分组。最好有示例。Pandas 的文档似乎好得多。 |
代码示例(也包括图形),记录每个用例 |
关于 dtype 转换的文档不完整,并且在用户指南中大体缺失。如果能清晰地解释转换规则(包括对 ndarray 的赋值),将使 NumPy 对新手更友好。还应包含一些常见的意外转换行为示例。 |
用户指南缺少形状中包含 0 的 ndarray 示例。这些在我的经验中经常出现,应该向新手更清楚地解释它们的广播机制。 |
NumPy 中存在许多或多或少冗余的函数。文档中包含 NumPy 惯用法(甚至是一本“食谱”)的部分将有助于澄清何时使用 ravel、reshape(-1) 或 flatten() 等问题。 |
提供关于如何使用 NumPy 对 ndarray 进行线性代数操作的全面指南。弄清楚从常规线性代数符号到一维和二维 ndarray 操作的映射(例如,添加 newaxis 以形成表示为一维 ndarray 的两个向量的外积)有点棘手。” |
文档应更详细且组织良好。 |
当我们通过搜索引擎查找信息时,我们经常会遇到与当前 NumPy 版本不符的文档;您需要一个与最新版本相对应的集中式文档(例如 Matlab 中存在的)。(此评论以法文提交。) |
更多示例和分章节的文档将帮助学习者 |
以任务为中心的教程/示例代码。scikit-learn.org 在这方面做得很好。 |
文档应该解释如何使用 NumPy 编写更大型的软件,而不仅仅是公式。 |
编写易于阅读的、特别是对学生/初学者友好的正确文档。 |
在技术细节之外,提供更详细的示例和教程。 |
最近文档确实有了很大的改进!我个人对文档/打包的兴趣是尝试确定如何将保存的 NumPy/稀疏矩阵正确地作为 pip 可安装库的一部分。 |
更详细的示例和解释,尤其是在傅里叶变换方面。 |
帮助从 Matlab 转换为 Python” |
确保每个 docstring 都有多个示例,并提供更详细的描述。 |
NumPy 将受益于像 scikit-learn 那样的用户指南。解释如何使用工具完成任务(而不仅仅是代码文档)的指南将使 NumPy 更易于接近,并吸引新用户(或激励老用户以新方式使用功能)。 |
扩展文档,明确记录已实现的方法及其各自的来源。 |
编写更多 NumPy 使用示例。 |
消除“import numpy as np” |
添加示例 |
添加一些(更多)快速入门和/或“操作指南”。确保文档中的所有示例代码都可以从网站上轻松下载。 |
我很难找到完成我所需任务的正确方法 |
更新 docstring 和错误消息,使其更易于理解 |
更简洁的 API 参考,旨在精确呈现可用例程及其语法 |
更多显示典型用法的示例代码。 |
帮助程序员了解如何最大限度地获得可移植的、可重现的结果,并实现程序的长期稳定性/可重复性/可再现性。 |
例如,让在网站上查找发布说明变得更容易(无需 Google 搜索);使这些说明清晰、简洁,并让非软件工程师的科学领域专家也能理解;并尽量减少他们为了保持旧程序运行而需要理解的编程细节(避免分散他们的工作注意力)。” |
正如最近指出的那样,“用户指南”部分有点像杂乱无章的非结构化材料,而大部分真正的用户文档都在“API 参考”中,后者结构良好,但最终却试图同时处理多项任务。 |
我们总是需要更多文档、教程和解决问题的博客文章。 |
NumPy 的用例(例如:何时使用标准库列表而不是 np.array()),面向初学者的 NumPy 教学课程, |
文档隐藏了实现细节,特别是试图掩盖与外部代码的接口,这是一个主要的缺点。 |
丰富示例代码。文档的日语支持。(此评论以日文提交。) |
我没有在 NumPy 文档中找到关于如何将 NumPy 链接到不同后端的说明。在某些函数中,接受字符串的关键字列出了不同的方法,但没有清楚地解释。 |
提供更多示例,不仅展示 API 如何工作,还提供基于性能的示例以及如何利用 NumPy 中存在的低级类型的示例 |
对学术知识要求较低的教程 |
标量类型、标量数组和 C 扩展 |
- 函数的可发现性。有时我知道我想做什么,但我不知道它可能叫什么名字,或者它可能在哪个子包中。不确定如何具体解决这个问题。 |
- 某些函数的文档不完整/模糊。我无法为您提供任何可以立即完成的事情;这将是一个缓慢的、逐个的努力” |
更多应用示例会很棒。 |
用例和一般宣传 |
NumPy 文档非常好,但有时能看到更多特定函数调用的示例或与内容相关的外部材料(例如维基百科页面)的引用会更好。 |
基本文档很好,但我希望为常见的(小型)任务提供更多超短示例 |
新功能¶
有 50 名参与者分享了他们对改进 NumPy 新功能的看法。
点击展开!
评论 |
|---|
我不一定只希望看到新功能,API 的轻微重新设计也会吸引我,例如,像 `numpy.apply_along_axis()` 这样的函数,我更倾向于将它们作为数组的方法,因为我相信这样会使代码更具可读性。 |
此外,我还想看到 Pandas 中存在的一些方法/函数,如 `pandas.Dataframe.pipe()` 或 `pandas.Dataframe.first_valid_Index()`。” |
将项目导出到不同的语言。(此评论以西班牙文提交。) |
支持 Golang API |
控制(传递函数)模块,像 Octave 的那样 |
向 random 模块添加新功能:多正态检验和 Copulas” |
n 维计算几何 |
分布式计算 |
如果能为计量经济学实现更多功能,同时通过新功能继续保持与竞争对手(R、Matlab 等)的竞争力,那就太好了。 |
我希望能够轻松地映射整个数组 |
更多对时间序列数据操作的支持。 |
并行计算。(此评论以中文提交。) |
更好地处理图,原生稀疏矩阵。 |
用于计算几何的 Nx2 数组 |
更好的图像到 NumPy 数组工具(可能与 OpenCV 结合) |
一些与复数值上的 ufunc 相关的相当深奥的东西 |
NumPy 不应仅限于 Python,而应将其可访问性扩展到其他编程语言。 |
它可以从更多便利功能中受益,例如 `one_hot` 函数。 |
在 `numpy.random` 中从广义逆高斯分布采样 |
并行化工具 |
Hadamard 矩阵 |
可定制的 dtype 系统,新的 dtype(例如 complex32、bfloat16 等),改进的类型支持,正交 ndarray 索引 |
由于经验不足,不确定,但添加新功能将有利于程序员使用。 |
可组合的操作,其行为类似于 ufuncs 并支持原地计算。numexpr 曾尝试过此功能,但非常有限。我在处理大量数据和更复杂计算时经常为此感到困扰。此外,可以扩展掩码操作。 |
更多统计功能 |
此外,上面提到的 GPU——我希望看到更具吸引力的打印选项。在我的演示笔记本中,我倾向于将数据移动到 Pandas,即使不需要,也是因为视图质量更好。 |
我不知道 :) 我通常在看到新版本时会感到惊喜。 |
我希望在 NumPy 中看到更多的统计方法,即像 SciPy 中那些。或者更准确地说,我希望在 SciPy 中看到 NumPy 的速度。或者反过来,即有 `numpy.var`、`numpy.std` 很好,但为什么没有 `numpy.skew` 和 `numpy.kurtosis` 呢? |
随机的特殊功能,例如快速重复矩阵乘积(y =a@b@c@…@z,其中 a-z 是小型方阵)、特征求解器、最小二乘求解器、图像处理 |
按组聚合。(此评论以日文提交。) |
我希望看到更丰富的统计功能集,例如 ANOVA 和多元回归建模。这是常见需要将数据移植到 R 的原因。 |
与可视化库更好地对齐 |
简化行阶梯形 |
原生 Rust 互操作性 |
- 使自定义 dtype 更容易(例如高效的字符串数组、分类数组、结构化数组的列式版本等)。 |
- 更好的 Pandas 互操作性(例如分类数组) |
- 锯齿状数组” |
更多 Cython 接口。 |
一些随机工具,例如其他语言中的 `im2row` 等效功能 |
* 识别空值或 None 值的方法,类似于 Pandas 的 `isnull()` 方法。这将有助于掩码/过滤。 |
* `Numpy.vectorize` 函数可以将性能从良好提升到优秀。我们是否可以实现真正的并行化,类似于 Numba 所做的那样(也许我要求太多了)https://chelseatroy.com/2018/11/07/code-mechanic-numpy-vectorization/” |
也许这已经存在了,但我希望看到一些方法,能够从用户指定方向的 3D 数组中生成切片。 |
将 C 后端模板转换为 C++ 模板。 |
分布式计算。 |
作为外部 Python 库的插件/扩展“ |
处理大数据的能力 |
添加像 IBM 浮点数这样的新数据类型会很好。开箱即用地添加惰性求值也会很好。 |
为此我将不得不更广泛地使用 NumPy。 |
dtypes 和 gufuncs 的可扩展性 |
自动微分 |
其他¶
有 9 名参与者将“其他”选为首要优先级
点击展开!
评论 |
|---|
我希望文档更明确,减少对行话的依赖。特别是从新手/业余程序员的角度来看,这将非常有帮助。 |
增加对 GPU 和并行操作的支持会很棒。 |
我的理解是,目前正在进行工作,以使 Python 科学生态系统中的 API 保持一致。我认为让各个组件融合并良好协作是高优先级事项。 |
NEP-35 样式的工作——使与 Dask 和 CuPy 的协作变得更容易 |
吸引更多代表性不足的人员为代码库做贡献。 |
通过提供低级 C 库与其他语言集成 |
继续进行弃用,并进行广泛的代码清理,移除不常用的内容,以创建更精简的代码库,旨在将 NumPy 构建为其他应用程序的坚实核心。 |
我认为 NumPy 作为 Python 数组的中心枢纽发挥着巨大作用。在这方面,我认为一个高优先级是改进互操作接口,以便其他库可以与 NumPy 无缝协作。这包括例如推动 HPy 项目以现代化 C 接口。 |
当然,NumPy 社区在改善组织(以及更广泛的 PyData 社区)的公平性和包容性方面仍有许多工作要做!” |
打包¶
有 13 名参与者分享了他们对如何改进 NumPy 打包工具的看法。
点击展开!
评论 |
|---|
不使用包管理器编译 NumPy 是一项相当艰巨的任务,至少我上次尝试时是这样。 |
为所有可能的架构和解释器提供 wheels 包 |
摆脱 NumPy distutils。改进 CI 并修复与支持新硬件(例如 Linux 上的 ARM64 和 Apple M1)相关的问题。 |
也许可以探索使用可重现构建来提高安全性并限制在 PyPI 或 conda-forge 上分发被编译器 rootkit 篡改的二进制文件的风险。” |
有时 NumPy 很难安装——特别是在没有自己的编译器的系统上。我曾尝试在 Windows 上安装,收到了令人困惑的错误消息,后来才知道是因为我的编译器设置不正确。有一次(很久以前)在 Linux 上,我需要安装系统头文件。我认为对于技术水平较低的用户来说,不得不求助于 Anaconda 来安装 Python 包不是一个好的用户体验。 |
一种简单的在安装后重建包的方法(例如,一个脚本,如“python -m numpy rebuild –library IntelMKL –options FMA”)。 |
在文档中更清楚地说明底层 BLAS/LAPACK 可能来自不同来源的事实!我花了几天时间询问 meep/tensorflow 为什么会通过强加它们的版本来破坏我的 NumPy 安装,而我却不明白为什么。” |
当前的系统有点老旧混乱,一些公开的 API 文档很差。此外,随着 Python 3.12 中 `distutils` 的消失,这可能是一个重要领域。重构和简化打包系统,要么依赖外部工具(如 setuptools、scikit-build 或其他),要么将构建系统分解为单独的包,这可能会有很大帮助。它还需要文档(例如如何构建 FORTRAN 扩展)。 |
NumPy 应该可以链接到 Windows 系统上的 Intel MKL,例如 Gohlke 存储库中分发的 wheels。这将极大地简化高度依赖 NumPy+MKL 提供速度的项目的维护。 |
持续关注帮助(并简化)发行版中的 NumPy 包保持最新 |
打包多年来有所改进,但在 Microsoft Windows 上的安装必须变得更加透明。 |
我的所有回答都关于保持现有状态 |
更好的发布信息 |
性能¶
有 72 名参与者分享了他们对性能为何是首要优先级以及如何改进性能的看法。
点击展开!
评论 |
|---|
允许 NumPy 访问 GPU 以并行执行任务 |
它已经很好了,我不知道还能如何改进 |
我的意思是“性能应该是首要优先级”。NumPy 已经表现出色——我认为这应该继续是一个优先级。 |
具体来说,是 Windows 上的性能,尽管我不确定这是否可行。 |
性能大多很好。调查迫使我选择一些优先级顺序,因此我认为性能、可靠性和文档对我的工作来说是最重要的。根据我的经验,NumPy 速度快、可靠且文档清晰。 |
向公众征集算法优化。(此评论以中文提交。) |
并行化。最佳实践教程。NumExpr 和 Numba 的高级教程。 |
在包含 NumPy、SciPy、Scikit-Learn 和其他更高级库的机器学习堆栈中,通过环境变量启用多线程在生产代码库中非常棘手(例如,在首次导入 NumPy 之前设置环境变量),目前根本不适用于我们的代码库(尽管它在一个简单的 PoC 代码片段中有效)。缺少超线程核心的检测和排除。动态与静态线程计数设置具有未文档化但重要的影响。所有这些在本地部署中都非常重要。 |
没什么可抱怨的,但我非常重视 NumPy 的性能 |
仍然有许多 NumPy 代码可以很容易地实现多线程,这将极大地提高我许多代码的性能。我知道外面有专门的库,但这会显著增加安装和维护的复杂性(特别是在有僵硬下载政策的公司内部),因此我尽量减少导入。 |
基本操作的多核支持会很好 |
CUDA 支持。支持 AMD 的 BLAS |
使用 GPU 和并行化 |
就速度而言,NumPy 非常棒,我可能更关心内存消耗,特别是对于 NumPy 掩码数组。 |
向量操作相关。(此评论以日文提交。) |
继续磨练底层(C)代码。 |
与 JAX 和 Dask 等项目联手。通过 f2py 或 LFortran 发展与现代 Fortran 更好的互操作性。 |
为欠发达国家的开发者开发 NumPy。经济欠发达地区的开发者拥有较低配置的电脑,因此开发能在低配置电脑上高性能运行的 NumPy 将对他们有所帮助。 |
我认为关于如何编写更快的 NumPy 代码的文档会很有帮助:向量化等。添加在计算中使用单位的能力。 |
在相同计算机上,Windows 上的性能比 Linux 差 |
使用 SIMD 代码来利用硬件向量化。 |
更好地支持 NumPy 与 GPU/CUDA 一起使用 |
减少开销 |
使其更快 |
提供一个 `min/max` 方法,可以一次性计算最小值/最大值,而不是先计算最小值再计算最大值。 |
小型计算机和大数据处理能力如何,而无需昂贵的 GPU、内存/处理器 |
开发更小的模块,以允许计算中更快的响应。(此评论以西班牙文提交。) |
允许多进程而不增加冗余。 |
NumPy 可以使用扩展指令集或针对 GPU。 |
将任意 Python 代码与广播一起应用时。(此评论以日文提交。) |
性能现在很好,但我使用 |
多节点 MKL |
你们做得很好……只是不要改变语法……让它尽可能保持原样 |
更多地推广西班牙语,如果我自私的话抱歉!(此评论以西班牙文提交。) |
CuPy 的原生支持,这样对我的大型数组(运行缓慢,这可能是 CPU 问题,而不是 NumPy 问题)会有帮助。尽管增加 GPU 支持会很棒。 |
提高计算速度。我所在领域的一些人因此转向 Julia。 |
我希望有集成的性能分析工具,可以指出矩阵操作中的瓶颈并提出替代方案。与 Numba 更紧密的集成也会非常好! |
为现代处理器提供 SIMD 指令(正如你们一直在做的),更具雄心的是,支持 OpenCL 和 Vulkan 等处理后端。 |
NumPy 是几乎成千上万软件开发工具链中的基础工具箱。如果某些功能能够得到改进以运行更快,它将在广泛的应用中产生巨大的影响。 |
没有特别的,但任何性能提升都可能产生巨大影响。 |
有些函数,例如 `np.unique`,与 Numba 不兼容,所以我希望有一个功能更精简的函数。(此评论以日文提交。) |
改善调用开销 |
增强向量化,多线程/SIMD 映射功能 |
- 更多地使用 SIMD 操作 - 也许与 Numba 进行一些集成,以实现操作的自动“融合”?对此不太确定…… |
自动化性能测试。如果可能的话,也许有一种方法可以提高 `vectorize` 函数的性能。 |
使用 VTune 分析内存并报告 CPU 和内存使用情况。 |
改进 GPU 支持。 |
我希望获得任何能让我的代码更快的东西 ;) |
老实说,NumPy 的性能令人惊叹。与 Python 通信的开销能否以某种方式减少? |
我认为没有简单的答案。支持和推动利用 DAG 和 JIT 的项目可能是最好的前进方向。这里的挑战在于这确实超出了 NumPy 的核心范围。 |
更好地与 CuPy(GPU)集成,多线程计算,可访问的选项用于定制您的个人构建(CPU 架构、BLAS 库……),理想情况下使用一个简单易用的脚本来重建包。支持 float16 |
对 Apple M1 芯片的原生优化 |
实际上,更多关于性能的文档会很棒 |
为一些关键操作(如二维规则分箱直方图,即图像)提供额外的编译例程。这主要只是一个要保留在优先级列表中的事项,因为有很多人依赖 NumPy 进行计算密集型代码。 |
对掩码数组的操作可能相当慢。 |
我想我并不是认为 NumPy 性能不佳,我只是希望它能做得更出色。我的模型涉及大量将有限差分法应用于偏微分方程并运行 10^6 次,所以任何一点性能提升都有帮助! |
向量化所有 API,支持通用函数。 |
这很难。我一时想不出什么,因为 NumPy 在大多数方面都设计得相当好。 |
神奇地让我的现有 NumPy 代码更快 🙂 |
进一步减重并加快处理速度。(此评论以日文提交。) |
它已经很好了,但它的主要弱点是它会产生中间数组——任何能导致更多运算符融合的技巧都值得赞赏! |
更好地支持 AMD 处理器 |
类似于 Julia 目前使用 LLVM 和 SIMD 的做法 |
进一步与 JAX 集成。也与 SciPy 集成 |
一些操作可以利用运算符融合,从而提高代码的内存带宽 |
如果有多方面知识和兴趣的人共同维护 NumPy,它就能得到改进。 |
- 可选的 TensorFlow 式操作链以节省内存带宽 - 为主要架构优化的定制低级代码 - 能够将代码卸载到加速器(例如 GPU),特别是如果这能以对用户透明的方式完成 |
设备放置 |
NumPy 的性能已经非常高,但性能对我来说非常重要。我使用 NumPy 是因为它的 API 很棒,而且我很少需要考虑性能。 |
我的大多数 API 都导入它,因此对导入的任何改进都将对我的项目导入时间产生广泛影响 |
我希望有 GPU 和多核设置的简单用户案例。 |
用户可扩展的 dtypes |
可靠性¶
有 58 名参与者分享了他们对可靠性以及如何改进可靠性的看法。
点击展开!
评论 |
|---|
我考虑的不是提高它,而是保持它的可靠性。 |
确保 API 向后兼容。 |
我认为 NumPy 是可靠的,这应该继续成为一个优先级。 |
NumPy 已经相当可靠了,我只是需要一个第二选择 |
补充了缺失的警告信息,并针对多线程进行了优化。(此评论以中文提交。) |
有几次(在 2020 年和 2021 年),我们不得不将 NumPy 的旧版本固定在 `requirements.txt` 中,因为它在 Windows 上已损坏。我们正在为 Linux 和 Windows 打包我们的本地生产代码变体。这种固定可能会以难以预测的方式影响依赖的机器学习库,并浪费时间。 |
没什么可抱怨的,但我非常重视 NumPy 的可靠性 |
使 NumPy API 随着时间的推移可持续发展。 |
许多科学项目都使用它。(此评论以法文提交。)” |
我不确定,但这需要在必要之前加以控制 |
自动化性能回归测试。参见例如工单 https://github.com/numpy/numpy/issues/18607 |
为每个包提供标准测试,以便在我们的计算机上进行基准测试 |
更少的破坏性更改 |
一些统计函数(例如 `quantile`)似乎并非 100% 可靠。我有点担心结果的准确性和精确度。 |
我知道做新东西很酷,但我相信,如果能投入大量精力来提高现有 NumPy 函数的可靠性,那将是非常棒的。 |
大多数科学编程(例如 SciPy)都依赖于 NumPy 的精度和基本功能,这就是为什么我认为可靠性至关重要。而且基准测试表现不佳:https://www.stochasticlifestyle.com/wp-content/uploads/2019/11/de_solver_software_comparsion.pdf” |
- 允许整数数组中包含 NaN。 |
- 寻找方法缓解使用日期时间时的不适。” |
更好的 CI 覆盖率。使用类型提示进行静态 linting。 |
它很棒,我只是认为其他事情的优先级较低。 |
优先考虑可靠性意味着我更看重它,而不是开发新功能。 |
长期稳定性,避免破坏性更改 |
没有发现其中的错误。发布测试用例和回归代码。 |
只需保持 NumPy 的稳定和可靠,因为它是许多项目的核心。 |
力求卓越、值得信赖的性能;无错误或疏忽相关问题。 |
使稀疏性成为一流概念 |
与性能一样,可靠性现在也很好,但我使用 |
NumPy 从未让我失望,但我明白要保持它运行需要大量工作。 |
NumPy 已经非常可靠了!我认为某种可视化内省工具将是一个很好的补充,有助于解决密集线性代数代码不按预期工作的一些“黑盒”问题,帮助程序员找到错误。 |
与之前的原因相同,该库是科学和工程领域多个不同工具包的基础支柱,因此提供正确的结果至关重要。 |
我记得在非常大的矩阵上处理线性代数时遇到过问题。我认为在最小二乘方程求解方面有一些问题,我不得不自己实现一些部分。除此之外,提供更有用的错误消息会更好。 |
安装 NumPy 并不真正健壮。我希望能在所有平台上解决这个问题 |
提供使用 NumPy 和其他工具(例如 Matlab)获得相同结果的比较。 |
继续处理错误报告,审查修复错误的 PR。 |
通过将非核心功能划分为插件模块并移除它们来减少和删除功能。为核心贡献者提供高级软件工程培训。分析缺陷注入点和过程。 |
系统化测试。目前它相当随意。 |
没有具体建议。这只是我关心的一点——知道如果我使用 NumPy 进行计算(我无法自己验证),它会是正确的。 |
更多各种平台的自动化测试。 |
我没有具体的建议。我的组织高度依赖我们使用的软件的可靠性。我怀疑许多其他用户也是如此。请永远不要为了“新功能”而牺牲可靠性/完整性。平台必须尽可能坚如磐石。 |
不需要 oldest-supported-numpy 包 |
专注于稳定性和修复错误,而不是添加新功能。 |
更少的“意外”。也许这真的属于更好的文档范畴。 |
* 减少现有错误或注意事项。 |
* API 接口的一致性。弃用那些会导致用户困惑的接口。” |
致力于实现计算结果的可移植再现性,以及与已发表科学论文相关的代码快照的长期稳定性/可重复性/可再现性。 |
我没有任何想法,只是觉得确保库的可靠性很重要。 |
GitHub 上有很多未解决的问题,这些可能会有帮助。此外,我有时在达到内存限制时会遇到奇怪的行为,但不知道在这方面能做些什么。 |
健康的错误积压 |
我们在医疗设备中使用 NumPy,让 NumPy 以可靠的方式运行,可以更轻松地升级以从错误修复、打包或性能改进中受益,而不会破坏现有代码 |
它已经很好了,但作为基础库,可靠性优先于其他方面,例如新功能。 |
NumPy 的依赖项数量庞大。尽可能长时间地不要破坏任何东西! |
持续关注无崩溃代码,并在不同平台提供一致的结果 |
我没有任何具体的抱怨,NumPy 非常可靠。对我来说,维护这一点比其他一些事项更重要,所以我把它排在前面。 |
NumPy 通常非常可靠,我只是认为可靠性对于一个数值库来说是必不可少的。请继续做你们出色的工作 :) |
NumPy 拥有出色的 API,并且已经涵盖了我想要使用的大部分功能。如果它也超级快且超级可靠,它基本上就是市面上最好的数值库了。 |
可靠性实际上相当好;请继续优先考虑它 |
可以开发一个涵盖 NumPy 几乎所有方面的详尽测试套件。这可以作为 NumPy 可靠性的基准。 |
这不是关于提高,而是要保持其当前的可靠性、性能等。 |
网站¶
最后,有 9 名参与者将 NumPy 网站选为首要优先级,并分享了他们对如何改进它的看法。
点击展开!
评论 |
|---|
用户友好的 UI |
该网站应该有更好的引用,当您使用搜索引擎查找问题答案时,应该能更快地到达那里。 |
不确定,但像“您可能还会对 xxx 感兴趣”这样的功能会有帮助!有时当我尝试做一些我从未做过的事情时,最终会发现有一个简单直接的方法可以做到,但需要花费很长时间才能找到。 |
前端……尝试使其用户友好 |
请提供更多西班牙语内容。 |
更多示例和教程。 |
更多示例! |
我很难找到完成我所需任务的正确方法。 |
教程 |
总结¶
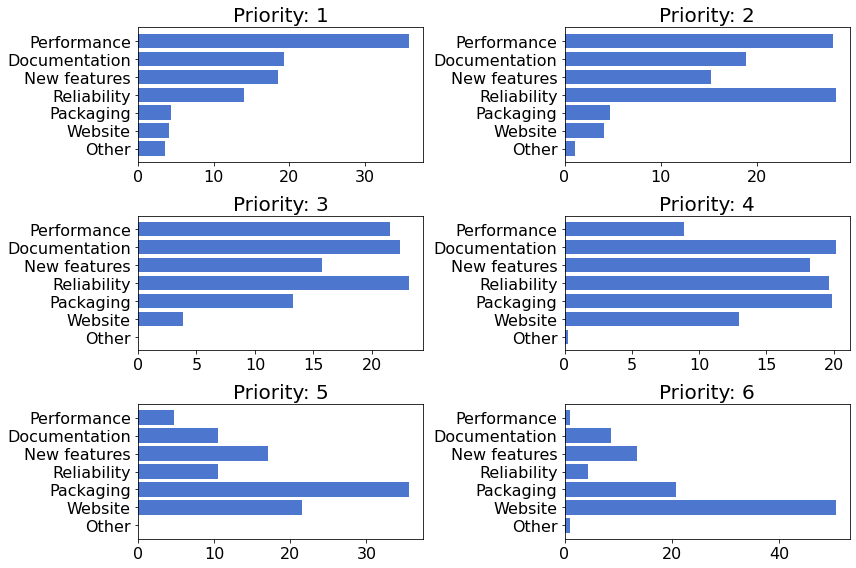
下图显示了所列的每个类别1在每个优先级级别的相对选择频率。
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
for i, ax in enumerate(axes.ravel()):
priority_level = i + 1
cnts = np.sum(raw == priority_level, axis=0)[I]
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title(f"Priority: {priority_level}")
fig.tight_layout()
- 1
不包括
Other,这是一个可选类别,因此构成了“最低优先级”的大部分。