

NEP 47 — 采纳数组 API 标准#
- 作者:
Ralf Gommers <ralf.gommers@gmail.com>
- 作者:
Stephan Hoyer <shoyer@gmail.com>
- 作者:
Aaron Meurer <asmeurer@gmail.com>
- 状态:
已取代
- 被取代者:
- 类型:
标准跟踪
- 创建日期:
2021-01-21
- 决议:
注意
此 NEP 已在 NumPy 1.22.0-1.26.x 中以实验性标签(导入时会发出警告)实现并发布。它在 NumPy 2.0.0 之前被移除,NumPy 2.0.0 开始在其主命名空间中支持数组 API 标准(参见 NEP 56 — NumPy 主命名空间中的数组 API 标准支持)。`numpy.array_api` 的代码已移至一个独立的包:array-api-strict。有关 `numpy.array_api` 模块的最后版本与 `numpy` 之间的详细区别,请参阅 1.26.x 文档中的此表格。
摘要#
我们提议采纳由 Python 数据 API 标准联盟开发的 Python 数组 API 标准。将其作为 NumPy 中一个独立的新命名空间实现,将使依赖 NumPy 的库的作者以及最终用户能够编写在 NumPy 和所有其他采纳此标准的数组/张量库之间可移植的代码。
注意
我们预计此 NEP 将在相当长的一段时间内保持草稿状态。鉴于其范围广阔,我们不期望在短期内提议其被接受;相反,我们希望就高层设计和实现征求反馈,并了解此 NEP 中需要更好描述或在实现或数组 API 标准本身中需要更改的内容。
动机与范围#
Python 用户在数值计算、数据科学、机器学习和深度学习的库和框架方面有丰富的选择。每年都有新的框架在这些领域推动技术前沿。所有这些活动和创造力的一个意外后果是多维数组(又称张量)库的碎片化——它们是这些领域的基本数据结构。选择包括 NumPy、TensorFlow、PyTorch、Dask、JAX、CuPy、MXNet 等等。
这些库的 API 大致相似,但差异足以使编写与多个(或所有)这些库一起工作的代码变得相当困难。数组 API 标准旨在通过为数组最常见的构建和使用方式指定 API 来解决这个问题。提议的 API 与 NumPy 的 API 非常相似,主要在以下方面存在差异:(a) NumPy 做出了一些设计选择,这些选择本质上不可移植到其他实现中,以及 (b) 其他库出于某种目的始终与 NumPy 存在差异,因为 NumPy 的设计被证明存在问题或不必要的复杂性。
有关数组 API 标准目的的更长讨论,请参阅 数组 API 标准的目的和范围部分以及宣布联盟成立 [1] 和发布标准第一个草稿版本以供社区审查 [2] 的两篇博文。
此 NEP 的范围包括
采纳 2021 年版本的数组 API 标准
添加一个单独的命名空间,暂定名为
numpy.array_api新命名空间之外所需/期望的更改,例如 `ndarray` 对象上的新 dunder 方法
实现选择,以及新命名空间中的函数与主
numpy命名空间中的函数之间的差异符合数组 API 标准的新数组对象
维护工作和测试策略
对 NumPy 总暴露 API 表面以及其他未来和正在讨论的设计选择的影响
与现有和提议的 NumPy 数组协议(
__array_ufunc__、__array_function__、__array_module__)的关系。对现有 NumPy 功能的必要改进
此 NEP 的范围不包括
数组 API 标准本身的更改。这些更改很可能在此 NEP 审查期间提出,但应根据需要上游化,并随后更新此 NEP。
用法与影响#
此部分将稍后充实,目前我们参考 数组 API 标准用例部分 中给出的用例
除了这些用例之外,新命名空间包含的功能被许多数组库广泛使用和支持。因此,它是向 NumPy 新手教授并推荐为“最佳实践”的良好函数集。这与 NumPy 的主命名空间形成对比,主命名空间包含许多已被取代或我们认为是错误的功能和对象——但由于向后兼容性原因我们无法移除它们。
下游库使用 numpy.array_api 命名空间旨在使其能够消费多种类型的数组,而无需硬性依赖所有这些数组库
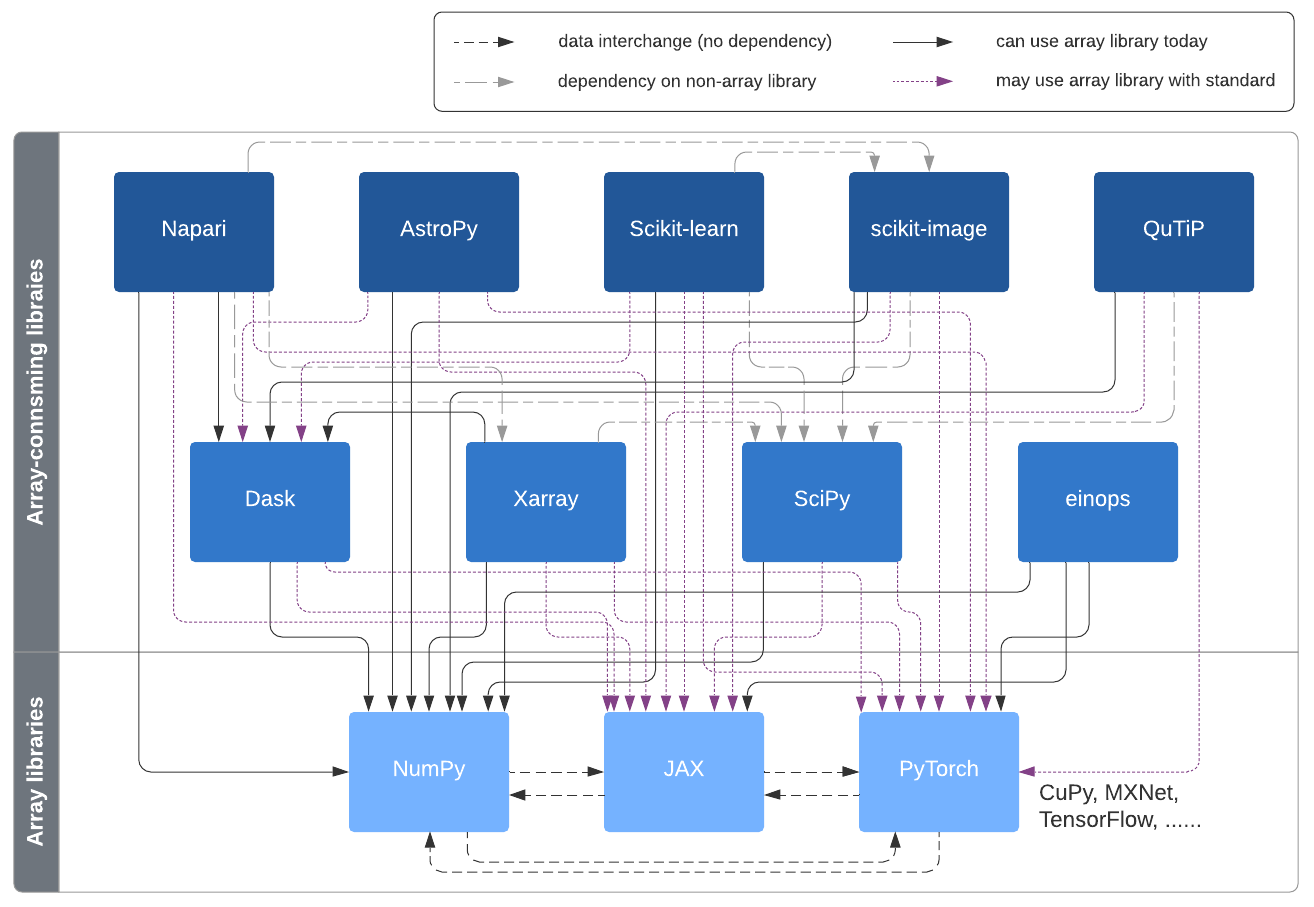
在下游库中的采纳#
原型实现中的 array_api 命名空间将与 SciPy、scikit-learn 和其他依赖 NumPy 的相关库一起使用,以便获得更多设计经验并找出是否缺少任何重要部分。
支持多个数组库的模式预计如下所示
def somefunc(x, y):
# Retrieves standard namespace. Raises if x and y have different
# namespaces. See Appendix for possible get_namespace implementation
xp = get_namespace(x, y)
out = xp.mean(x, axis=0) + 2*xp.std(y, axis=0)
return out
get_namespace 调用实际上是库作者选择使用标准 API 命名空间,从而明确支持所有符合标准的数组库。
``asarray`` / ``asanyarray`` 模式#
许多现有库使用与 NumPy 本身相同的 asarray(或 asanyarray)模式;接受任何可以强制转换为 np.ndarray 的对象。我们认为这种设计模式有问题——考虑到 Python 之禅中的“显式优于隐式”,以及该模式在 SciPy 生态系统中对于 ndarray 子类和过度急切的对象创建的历史问题。所有其他数组/张量库都更严格,并且在实践中运行良好。我们建议新库的作者避免使用 asarray 模式。相反,他们应该只接受 NumPy 数组,或者,如果他们想支持多种类型的数组,通过检查是否存在 __array_namespace__ 来检查传入的数组对象是否支持数组 API 标准,如上面的示例所示。
现有库也可以进行此类检查,并且只有在检查失败时才调用 asarray。这与 NEP 30 — NumPy 数组的鸭子类型——实现 中的 __duckarray__ 思想非常相似。
在应用程序代码中的采纳#
最终用户可以将新的命名空间视为 NumPy 主命名空间的一个精简和清理版本。鼓励最终用户像这样使用此命名空间
import numpy.array_api as xp
x = xp.linspace(0, 2*xp.pi, num=100)
y = xp.cos(x)
看起来完全合理,并且可能是有益的——用户每个目的只获得一个函数(我们认为是最佳实践的那个),然后他们编写的代码更容易移植到其他库。
向后兼容性#
未提议弃用或移除现有 NumPy API 或其他向后不兼容的更改。
高层设计#
数组 API 标准包含大约 120 个对象,所有这些对象都有一个直接的 NumPy 等效项。此图显示了高层包含的内容
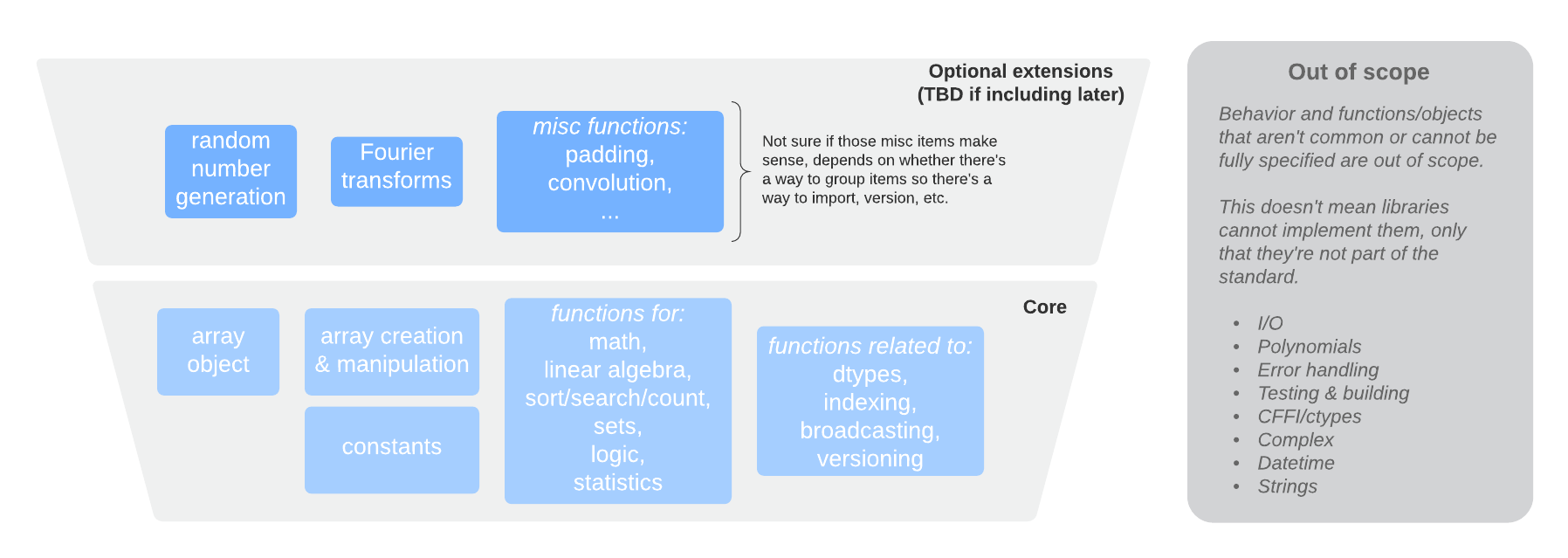
与 NumPy 当前提供的功能相比,最重要的变化是
一个新的数组对象,
numpy.array_api.Array,它是
np.ndarray的一个薄的纯 Python(非子类)包装器,符合标准指定的类型转换规则和索引行为,
除了 dunder 方法外没有其他方法,
不支持 NumPy 完整的索引行为(见下文 索引),
没有独立的标量对象,只有 0 维数组,
不能直接构造。相反,应使用
asarray()等数组构造函数。
array_api命名空间中的函数不接受
array_like输入,只接受numpy.array_api数组对象,Python 标量仅在数组对象的 dunder 运算符中受支持,不支持
__array_ufunc__和__array_function__,在其签名中使用仅位置参数和仅关键字参数,
具有内联类型注解,
与 NumPy 中已有的等效函数相比,单个函数的签名和语义可能略有更改,
只支持 dtype 字面量,不支持格式字符串或其他指定 dtypes 的方式,
通常可能只支持与 NumPy 对应项相比受限的 dtypes 集合。
DLPack 支持将添加到 NumPy 中,
将添加“设备支持”的新语法,通过新数组对象上的
.device属性,以及array_api命名空间中数组创建函数中的device=关键字,类型转换规则将与 NumPy 当前的规则不同。输出 dtypes 可以从输入 dtypes 派生(即,没有基于值的类型转换),并且 0 维数组被视为 >=1 维数组。不允许跨种类类型转换(例如,int 到 float)。
NumPy 拥有的所有 dtypes 并非都属于标准。只支持布尔、有符号和无符号整数,以及最高
float64的浮点 dtypes。预计将在下一版本标准中添加复数 dtypes。扩展精度、字符串、void、对象和 datetime dtypes,以及结构化 dtypes,均不包括在内。
所需的现有 NumPy 功能改进包括
为
numpy.linalg中目前缺少此支持的一些函数添加矩阵堆栈支持。为
np.argmin和np.argmax添加keepdims关键字。为
np.asarray添加“永不复制”模式。将 smallest_normal 添加到
np.finfo()。DLPack 支持。
此外,numpy.array_api 实现被选择为数组 API 标准的最小实现。这意味着它不仅符合数组 API 的所有要求,而且明确不包含任何未明确要求的 API 或行为。标准本身不要求实现如此严格,但将 NumPy 数组 API 实现如此限制将使其成为数组 API 标准的规范实现。任何想要使用数组 API 标准的人都可以使用 NumPy 实现,并确信他们的代码没有使用在其他符合标准的实现中可能不存在的行为。
具体来说,这意味着
numpy.array_api将只包含标准中列出的那些函数。这也适用于Array对象上的方法,函数将只接受标准要求的输入 dtypes(例如,像
cos这样的超越函数将不接受整数 dtypes,因为标准只要求它们接受浮点 dtypes),类型提升将只发生在标准要求的 dtypes 组合中(参见下面的 DType 和类型转换规则 部分),
索引仅限于可能的索引类型的一个子集(参见下面的 索引)。
array_api 命名空间中的函数#
让我们从一个函数实现的例子开始,它展示了与主命名空间中等效函数最重要的区别
def matmul(x1: Array, x2: Array, /) -> Array:
"""
Array API compatible wrapper for :py:func:`np.matmul <numpy.matmul>`.
See its docstring for more information.
"""
if x1.dtype not in _numeric_dtypes or x2.dtype not in _numeric_dtypes:
raise TypeError("Only numeric dtypes are allowed in matmul")
# Call result type here just to raise on disallowed type combinations
_result_type(x1.dtype, x2.dtype)
return Array._new(np.matmul(x1._array, x2._array))
此函数不接受 array_like 输入,只接受 numpy.array_api.Array。这有多个原因。其他数组库都这样工作。要求用户显式地强制转换 Python 标量、列表、生成器或其他外部对象会带来更清晰的设计,减少意外行为。它的性能更高——asarray 调用的开销更少。静态类型更容易。子类将按预期工作。而且,由于用户在少数情况下必须显式强制转换为 ndarray 导致稍微增加的冗长性,似乎是微不足道的代价。
此函数不支持 __array_ufunc__ 也不支持 __array_function__。这些协议与数组 API 标准模块本身具有相似的目的,但通过不同的机制。因为只接受 Array 实例,所以通过这些协议之一进行调度不再有用。
此函数在其签名中使用仅位置参数。这使得代码更具可移植性——例如,编写 max(a=a, ...) 不再有效,因此如果其他库将第一个参数称为 input 而不是 a,那也无妨。请注意,NumPy 已经对 ufuncs 函数使用仅位置参数。仅关键字参数(未在上述示例中显示)的理由有两个:最终用户代码的清晰度,以及将来扩展签名时更容易,而无需担心关键字的顺序。
此函数具有内联类型注解。内联注解比单独的存根文件更容易维护。而且由于类型很简单,这不会导致大量的类型别名或联合的混乱,就像 NumPy 当前的存根文件那样。
此函数仅接受数值 dtypes(即不接受 bool)。它也不允许输入 dtypes 为不同种类(内部 _result_type() 函数将对跨种类类型组合(如 _result_type(int32, float64))引发 TypeError)。这使得实现可以最小化。阻止在 NumPy 中有效但数组 API 规范不要求的组合,可以让子模块的用户知道他们没有依赖 NumPy 特定的行为,而这些行为可能不存在于其他库中符合数组 API 的实现中。
DLPack 支持零拷贝数据交换#
将一种类型的数组转换为另一种类型的能力是很有价值的,并且当下游库想要支持多种类型的数组时,这确实是必要的。这需要一个定义明确的数据交换协议。NumPy 已经支持其中两种,即缓冲区协议(即 PEP 3118)和 __array_interface__(Python 端)/ __array_struct__(C 端)协议。两者工作方式相似,都允许“生产者”描述数据在内存中的布局方式,以便“消费者”可以构造自己的数组类型,并对数据进行视图。
DLPack 的工作方式非常相似。选择 DLPack 而非 NumPy 中已有的选项的主要原因在于
DLPack 是唯一支持设备的协议(例如,使用 CUDA 或 ROCm 驱动程序的 GPU,或 OpenCL 设备)。NumPy 仅支持 CPU,但其他数组库则不然。每个设备一个协议是不可行的,因此设备支持是必须的。
广泛支持。DLPack 在所有协议中采用最广泛。只有 NumPy 缺少支持,其他库对其的经验是积极的。这与 NumPy 支持的协议形成对比,这些协议使用很少——当其他库想要与 NumPy 互操作时,它们通常使用(更有限、NumPy 特有的)
__array__协议。
向 NumPy 添加 DLPack 支持需要
添加一个
ndarray.__dlpack__()方法,该方法返回一个包装在PyCapsule中的dlpackC 结构体。添加一个
np.from_dlpack(obj)函数,其中obj支持__dlpack__(),并返回一个ndarray。
DLPack 目前是一个大约 200 行代码的头文件,旨在直接包含,因此不需要外部依赖。实现应该很简单。
设备支持的语法#
NumPy 本身只支持 CPU,所以它显然不需要设备支持。然而,其他库(例如 TensorFlow、PyTorch、JAX、MXNet)支持多种类型的设备:CPU、GPU、TPU 以及更奇特的硬件。为了在具有多个设备的系统上编写可移植代码,通常需要创建与某些其他数组位于相同设备上的新数组,或者检查两个数组是否位于相同设备上。因此需要相应的语法。
数组对象将有一个 .device 属性,它允许比较不同数组的设备(只有当两个数组来自同一个库并且是相同的硬件设备时,它们才应该比较相等)。此外,在数组创建函数中需要 device= 关键字。例如
def empty(shape: Union[int, Tuple[int, ...]], /, *,
dtype: Optional[dtype] = None,
device: Optional[device] = None) -> Array:
"""
Array API compatible wrapper for :py:func:`np.empty <numpy.empty>`.
"""
if device not in ["cpu", None]:
raise ValueError(f"Unsupported device {device!r}")
return Array._new(np.empty(shape, dtype=dtype))
NumPy 的实现很简单,只需将设备属性设置为字符串 "cpu",并在数组创建函数遇到任何其他值时引发异常。
DType 和类型转换规则#
此命名空间中支持的 dtypes 有布尔型、8/16/32/64 位有符号和无符号整数型,以及 32/64 位浮点型。这些将作为 dtype 字面量添加到命名空间中,具有预期的名称(例如,bool、uint16、float64)。
最明显的遗漏是复数 dtypes。数组 API 标准第一个版本缺少复数支持的原因是,几个库(PyTorch、MXNet)仍在添加对复数 dtypes 的支持。标准的下一版本预计将包含 complex64 和 complex128(更多细节请参见 此问题)。
向函数指定 dtypes(例如,通过 dtype= 关键字)预计只使用 dtype 字面量。格式字符串、Python 内置 dtypes 或 dtype 字面量的字符串表示形式均不接受。这将以很小的代价提高代码的可读性和可移植性。此外,除了基本的相等比较之外,这些 dtype 字面量本身预计不会有任何行为。特别是,由于数组 API 没有标量对象,因此不允许使用 float32(0.0) 这样的语法(可以使用 asarray(0.0, dtype=float32) 创建 0 维数组)。
类型转换规则仅在同一种类的不同 dtypes 之间定义(即,布尔型到布尔型,整数型到整数型,或浮点型到浮点型)。这也意味着省略 NumPy 中会向上转换为 float64 的整数-uint64 组合。这样做的理由是,不同库之间的混合种类(例如,整数到浮点数)类型转换行为有所不同。
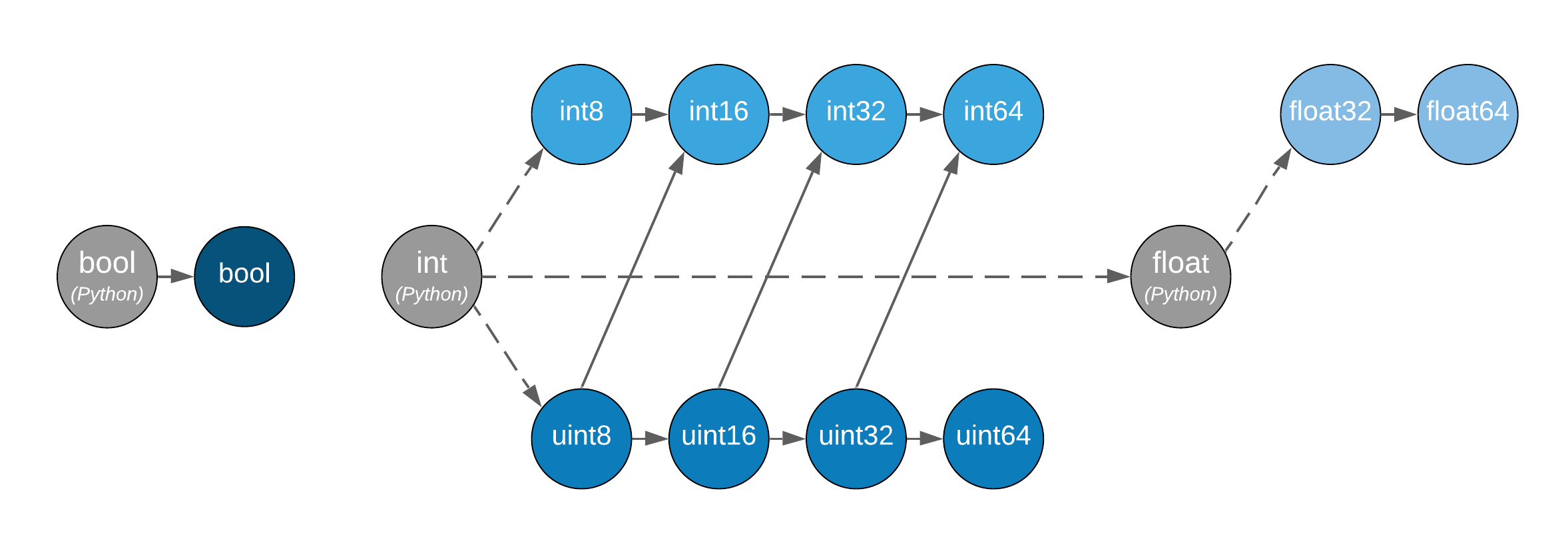
类型提升图。任意两种类型之间的提升由它们在此格上的连接给出。只考虑参与数组的类型,不考虑它们的值。虚线表示 Python 标量溢出时的行为未定义。Python 标量本身只允许在数组对象的运算符中使用,不能在函数内部使用。布尔型、整数型和浮点型 dtypes 未连接,表示混合种类提升未定义(对于 NumPy 实现,这些会引发异常)。
NumPy 和数组 API 标准中的类型转换规则之间最重要的区别在于标量和 0 维数组的处理方式。在标准中,数组标量不存在,0 维数组遵循与高维数组相同的类型转换规则。此外,标准中没有基于值的类型转换。操作的结果类型可以完全根据其输入数组的 dtypes 预测,无论它们的形状或值如何。Python 标量只允许在 dunder 操作(如 __add__)中使用,并且仅当它们与数组 dtype 属于同一种类时。它们总是转换为数组的 dtype,无论值如何。溢出行为未定义。
有关详细信息,请参阅 数组 API 标准的类型提升规则部分。
在实现中,这意味着
确保任何在 NumPy 中会产生标量对象的运算,在
Array构造函数中被转换为 0 维数组,检查那些会应用基于值的类型转换的组合,并确保它们提升到正确的类型。这可以通过例如手动广播 0 维输入(阻止它们参与基于值的类型转换),或者显式地将
signature参数传递给底层 ufunc 来实现,在 dunder 运算符方法中,如果 Python 标量输入与 dtype 匹配且同种类,则手动将其转换为匹配 dtype 的 0 维数组,否则引发异常。对于超出给定 dtype 范围的标量(其行为未由规范定义),将使用
np.array(scalar, dtype=dtype)的行为(要么转换,要么引发 OverflowError)。
索引#
一个在 ndarray 中会返回标量的索引表达式,例如 arr_2d[0, 0],在新 Array 对象中将返回一个 0 维数组。这有几个原因:数组标量在很大程度上被认为是一个设计错误,其他数组库都没有复制;它对非 CPU 库(通常数组可以存在于设备上,标量存在于主机上)工作得更好;它只是一个更一致的设计。要从 0 维数组中获取 Python 标量,可以使用该类型的内置函数,例如 float(arr_0d)。
标准中的其他 索引模式 工作方式与 numpy.ndarray 大致相同。一个值得注意的区别是,切片索引中的剪裁(例如,a[:n] 中 n 大于第一个轴的大小)是未指定行为,因为这种检查在加速器上可能开销很大。
标准省略了高级索引(通过整数数组进行索引),并且布尔索引仅限于单个 n 维布尔数组。这是因为这些索引模式不适用于所有类型的数组或 JIT 编译。此外,一些高级 NumPy 索引语义,例如在单个索引中混合高级和非高级索引的语义,在 NumPy 中被认为是设计错误。缺少这些更高级的索引类型似乎不是问题;如果用户或库作者想要使用它们,他们可以通过零拷贝转换到 numpy.ndarray 来实现。这将正确地向阅读代码的人发出信号,表明它现在是 NumPy 特定的,而不是可移植到所有符合标准的数组类型。
作为最小实现,numpy.array_api 将明确禁止带剪裁边界的切片、高级索引以及布尔索引与其它索引混合使用。
数组对象#
标准中的数组对象除了 dunder 方法外没有其他方法。它也不允许直接构造,而是倾向于使用 asarray 等数组构造方法。这样做的理由是并非所有数组库在其数组对象上都有方法(例如 TensorFlow 没有)。它还只提供一种做事方式,而不是有多个实际上是重复的函数和方法。
混合可能产生视图的操作(例如,索引、nonzero)与修改操作(例如,项或切片赋值)的组合是 标准中明确指出不支持 的。这不能轻易地在数组对象本身中禁止;相反,这将通过文档向用户提供指导。
标准目前并未规定数组对象本身的名称。我们提议将其命名为 Array。这符合 PEP 8 对类的正确大写约定,并且不与任何现有 NumPy 类名冲突。[3] 请注意,数组类的实际名称并不那么重要,因为它本身不包含在顶级命名空间中,也无法直接构造。
实现#
array_api 命名空间的原型可以在 numpy/numpy#18585 中找到。其 __init__.py 中的文档字符串包含几个关于实现细节的重要说明。包装函数的代码也包含 # Note: 注释,标注了与 NumPy API 的所有不同之处。该实现完全采用纯 Python,主要由包装类/函数组成,它们在应用输入验证和任何更改的行为后,将调用传递给相应的 NumPy 函数。尚未实现的一个重要部分是 DLPack 支持,因为其在 np.ndarray 中的实现仍在进行中(numpy/numpy#19083)。
numpy.array_api 模块被认为是实验性的。这意味着导入它会发出 UserWarning。替代方案是将模块命名为 numpy._array_api,但选择了警告,以便将来无需重命名模块,从而可能破坏用户代码。由于广泛使用仅位置参数语法,该模块还需要 Python 3.8 或更高版本。
模块的实验性质也意味着除了其模块文档字符串和此 NEP 之外,它尚未在 NumPy 文档的任何地方提及。实现的文档本身就是一个具有挑战性的问题。目前,实现中的每个文档字符串都只引用它所实现的底层 NumPy 函数。然而,这并不理想,因为底层 NumPy 函数的行为可能与数组 API 中相应的函数不同,例如,数组 API 中不存在的额外关键字参数。有人建议文档可以直接从规范本身中提取,但这需要对规范的编写方式进行一些技术更改才能支持,因此当前的实现尚未尝试这样做。
数组 API 规范附带了一个正在进行中的 官方测试套件,旨在测试任何库对数组 API 规范的符合性。因此,实现中包含的测试将是最小的,因为大部分行为将由该测试套件进行验证。NumPy 自身中用于 array_api 子模块的测试将只包括测试数组 API 测试套件未涵盖的行为,例如,测试实现是否最小化并正确拒绝不允许的类型组合。CI 作业将添加到数组 API 测试套件仓库中,以定期针对 NumPy 实现进行测试。数组 API 测试套件被设计为如果库希望这样做可以将其包含在内,但 NumPy 拒绝了这一想法,因为它相对于现有 NumPy 测试套件所花费的时间很长,并且因为测试套件本身仍在进行中。
dtype 对象#
我们必须能够比较 dtypes 的相等性,并且以下表达式必须是可能的
np.array_api.some_func(..., dtype=x.dtype)
以上意味着如果 np.array_api.float32 == np.array_api.ndarray(...).dtype 会很好。
不应假设用户会将 dtypes 视为具有类层次结构,但是如果方便,我们可以自由地使用类层次结构来实现它。我们考虑了以下选项来实现 dtype 对象
将 dtypes 别名为主命名空间中的 dtypes,例如,
np.array_api.float32 = np.float32。使 dtypes 成为
np.dtype的实例,例如,np.array_api.float32 = np.dtype(np.float32)。创建只有所需方法/属性(目前只有
__eq__)的新单例类。
从与主命名空间外部的函数交互的角度来看,(2) 似乎最简单,而 (3) 最符合标准。(2) 不会像 (3) 那样阻止用户访问 dtype 对象的 NumPy 特定属性,尽管与 (1) 不同的是,它确实不允许创建像 float32(0.0) 这样的标量对象。(2) 还为每个 dtype 只保留一个对象——使用 (1),arr.dtype 仍然是一个 dtype 实例。目前的实现使用 (2)。
待定:标准尚未有检查 dtype 属性的好方法,例如询问“这是否是整数 dtype?”。也许这对于用户来说足够简单,如下所示
def _get_dtype(dt_or_arr):
return dt_or_arr.dtype if hasattr(dt_or_arr, 'dtype') else dt_or_arr
def is_floating(dtype_or_array):
dtype = _get_dtype(dtype_or_array)
return dtype in (float32, float64)
def is_integer(dtype_or_array):
dtype = _get_dtype(dtype_or_array)
return dtype in (uint8, uint16, uint32, uint64, int8, int16, int32, int64)
然而,将其添加到标准中可能更有意义。请注意,NumPy 本身目前还没有一个很好的方法来提问此类问题,请参阅 gh-17325。
替代方案#
有人提议将 NumPy 数组 API 实现作为一个独立的库,而不是 NumPy 的一部分。这一提议被否决了,因为将其独立将使其审查可能性降低,而将其作为实验性子模块包含在 NumPy 本身中将更容易让已经依赖 NumPy 的最终用户和库作者访问该实现。
附录 - 可能的 get_namespace 实现#
在应用程序代码中的采纳 部分提及的 get_namespace 函数可以这样实现
def get_namespace(*xs):
# `xs` contains one or more arrays, or possibly Python scalars (accepting
# those is a matter of taste, but doesn't seem unreasonable).
namespaces = {
x.__array_namespace__() if hasattr(x, '__array_namespace__') else None for x in xs if not isinstance(x, (bool, int, float, complex))
}
if not namespaces:
# one could special-case np.ndarray above or use np.asarray here if
# older numpy versions need to be supported.
raise ValueError("Unrecognized array input")
if len(namespaces) != 1:
raise ValueError(f"Multiple namespaces for array inputs: {namespaces}")
xp, = namespaces
if xp is None:
raise ValueError("The input is not a supported array type")
return xp
讨论#
参考文献和脚注#
版权#
本文档已置于公共领域。 [1]