

NEP 13 — 覆盖 Ufunc 的机制#
- 作者:
Blake Griffith
- 联系方式:
- 日期:
2013-07-10
- 作者:
Pauli Virtanen
- 作者:
Nathaniel Smith
- 作者:
Marten van Kerkwijk
- 作者:
Stephan Hoyer
- 日期:
2017-03-31
- 状态:
最终版
- 更新:
2023-02-19
- 作者:
Roy Smart
执行摘要#
NumPy 的通用函数 (ufuncs) 目前对于操作用户定义的 ndarray 子类具有一些有限的功能,使用 __array_prepare__ 和 __array_wrap__ [1],但对于任意对象(例如 SciPy 的稀疏矩阵 [2] [3])则几乎没有支持。
在此,我们提议添加一种机制来覆盖 Ufunc,该机制基于 Ufunc 检查其每个参数是否存在 __array_ufunc__ 方法。一旦发现 __array_ufunc__,Ufunc 将操作交给该方法处理。
这与 Travis Oliphant 提议为 NumPy 追加多方法(retro-fit NumPy with multi-methods)的某些内容重叠 [4],后者也能解决相同问题。这里的机制更紧密地遵循 Python 允许类覆盖 __mul__ 和其他二元操作的方式。它还专门解决了二元运算符和 Ufunc 应该如何交互的问题。(请注意,在早期版本中,此覆盖机制被称为 __numpy_ufunc__。曾实现过一个版本,但行为不完全正确,因此更改了名称。)
如下文所述的 __array_ufunc__ 要求任何相应的 Python 二元操作(__mul__ 等)必须以特定方式实现,并与 NumPy 的 ndarray 语义兼容。不满足此条件的对象无法覆盖任何 NumPy Ufunc。我们未指定可放宽此要求的未来兼容路径 — 任何更改都将需要第三方代码进行相应更改。
动机#
目前的 Ufunc 调度机制普遍被认为不足。已经进行了长时间的讨论并提出了其他解决方案 [5], [6]。
将 Ufunc 与 ndarray 的子类一起使用时,仅限于使用 __array_prepare__ 和 __array_wrap__ 来准备输出参数,但这些方法不允许你例如更改参数的形状或数据。尝试对不继承自 ndarray 的对象进行 Ufunc 操作则更加困难,因为输入参数往往会被转换为对象数组,从而产生令人惊讶的结果。
以 Ufunc 与稀疏矩阵的互操作性为例。
In [1]: import numpy as np
import scipy.sparse as sp
a = np.random.randint(5, size=(3,3))
b = np.random.randint(5, size=(3,3))
asp = sp.csr_matrix(a)
bsp = sp.csr_matrix(b)
In [2]: a, b
Out[2]:(array([[0, 4, 4],
[1, 3, 2],
[1, 3, 1]]),
array([[0, 1, 0],
[0, 0, 1],
[4, 0, 1]]))
In [3]: np.multiply(a, b) # The right answer
Out[3]: array([[0, 4, 0],
[0, 0, 2],
[4, 0, 1]])
In [4]: np.multiply(asp, bsp).todense() # calls __mul__ which does matrix multi
Out[4]: matrix([[16, 0, 8],
[ 8, 1, 5],
[ 4, 1, 4]], dtype=int64)
In [5]: np.multiply(a, bsp) # Returns NotImplemented to user, bad!
Out[5]: NotImplemented
向用户返回 NotImplemented 不应该发生。此外,
In [6]: np.multiply(asp, b)
Out[6]: array([[ <3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>],
[ <3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>],
[ <3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>,
<3x3 sparse matrix of type '<class 'numpy.int64'>'
with 8 stored elements in Compressed Sparse Row format>]], dtype=object)
在这里,稀疏矩阵似乎被转换成了一个对象数组标量,然后与 b 数组的所有元素相乘。然而,这种行为与其说有用不如说令人困惑,最好是抛出 TypeError。
本提案不会解决 scipy.sparse 矩阵的问题,因为它们的乘法语义与 NumPy 数组不兼容。然而,其目标是支持编写其他具有严格 ndarray 兼容语义的自定义数组类型。
提议的接口#
标准数组类 ndarray 获得一个 __array_ufunc__ 方法,并且对象可以通过覆盖此方法(如果它们是 ndarray 子类)或定义自己的方法来覆盖 Ufunc。方法签名如下:
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs)
这里
ufunc 是被调用的 Ufunc 对象。
method 是一个字符串,指示 Ufunc 的调用方式,可以是
"__call__"表示直接调用,也可以是其方法之一:"reduce"、"accumulate"、"reduceat"、"outer"或"at"。inputs 是
ufunc的输入参数元组kwargs 包含传递给函数的任何可选或关键字参数。这包括任何
out参数,这些参数始终包含在元组中。
因此,参数被标准化:只有必需的输入参数(inputs)作为位置参数传递,所有其他参数都作为关键字参数字典(kwargs)传递。特别地,如果存在非 None 的输出参数(无论是否是位置参数),它们都将作为元组传递给 out 关键字参数(即使对于 reduce、accumulate 和 reduceat 方法,在所有当前情况下只有一个输出有意义)。
函数调度流程如下:
如果输入、输出或
where参数之一实现了__array_ufunc__,则执行该方法而非 Ufunc。如果多个参数实现了
__array_ufunc__,则按以下顺序尝试:子类先于超类,输入先于输出,输出先于where,否则从左到右。第一个返回非
NotImplemented的__array_ufunc__方法决定 Ufunc 的返回值。如果所有输入参数的
__array_ufunc__方法都返回NotImplemented,则抛出TypeError。如果
__array_ufunc__方法引发错误,该错误将立即传播。如果所有输入参数都没有
__array_ufunc__方法,则执行将回退到默认的 Ufunc 行为。
在上述规定中,有一个附加条件:如果一个类具有 __array_ufunc__ 属性,但其与 ndarray.__array_ufunc__ 相同,则该属性将被忽略。这发生在 ndarray 的实例以及未覆盖其继承的 __array_ufunc__ 实现的 ndarray 子类上。
类型转换层级#
Python 运算符覆盖机制在如何编写覆盖方法方面提供了很大的自由度,并且为了实现可预测的结果,需要一定的规程。在此,我们讨论一种理解其某些影响的方法,这可以为设计提供输入。
保持清晰地了解哪些类型可以“向上转换”到其他类型(可能是间接的,例如实现了间接的 A->B->C 但未实现直接的 A->C)是非常有用的。如果 __array_ufunc__ 的实现遵循连贯的类型转换层级,就可以用它来理解操作结果。
类型转换可以表示为如下定义的图:
对于每个
__array_ufunc__方法,从每个可能的输入类型到每个可能的输出类型绘制有向边。也就是说,在每次
y = x.__array_ufunc__(a, b, c, ...)执行了除返回NotImplemented或引发错误以外的操作时,绘制边type(a) -> type(y),type(b) -> type(y), …
如果生成的图是非循环的,它就定义了一个连贯的类型转换层级(类型之间明确的部分排序)。在这种情况下,涉及多种类型的操作通常会可预测地产生“最高”类型的结果,或者引发 TypeError。请参阅本节末尾的示例。
如果图中有循环,则 __array_ufunc__ 类型转换未明确定义,并且不排除诸如 type(multiply(a, b)) != type(multiply(b, a)) 或 type(add(a, add(b, c))) != type(add(add(a, b), c)) 的情况(并且可能总是存在)。
如果类型转换层级定义良好,对于每个类 A,所有其他定义 __array_ufunc__ 的类都恰好属于三个组之一:
A 以上:在 Ufunc 中 A 可以(间接)向上转换到的类型。
A 以下:可以(间接)向上转换到 A 的类型。
不兼容:既不在 A 以上也不在 A 以下;无法进行(间接)向上转换的类型。
请注意,NumPy Ufunc 的传统行为是尝试通过 np.asarray() 将未知对象转换为 ndarray。这等同于在图中将 ndarray 放在这些对象之上。由于我们上面将 ndarray 定义为对于具有自定义 __array_ufunc__ 的类返回 NotImplemented,这使得 ndarray 在类型层级中位于此类之下,从而允许覆盖操作。
鉴于上述情况,描述传递操作的二元 Ufunc 应致力于定义一个明确的转换层级。这可能也是所有 Ufunc 的合理方法——对此的例外情况应仔细考虑是否会产生任何令人惊讶的行为。
示例
类型转换层级。
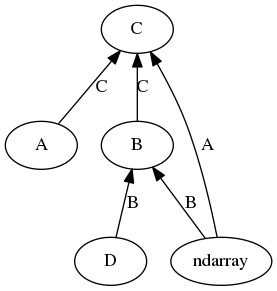
类型 A 的 __array_ufunc__ 可以处理返回 C 的 ndarray,B 可以处理返回 B 的 ndarray 和 D,C 可以处理返回 C 的 A 和 B,但不能处理 ndarray 或 D。结果是一个有向无环图,并定义了一个类型转换层级,关系为 C > A, C > ndarray, C > B > ndarray, C > B > D。类型 A 与 B、D、ndarray 不兼容,D 与 A 和 ndarray 不兼容。涉及这些类的 Ufunc 表达式应产生所涉最高类型的结果,否则将引发 TypeError。
示例
__array_ufunc__ 图中的一个循环。
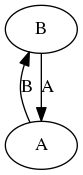
在这种情况下,__array_ufunc__ 关系有一个长度为 1 的循环,并且不存在类型转换层级。二元操作不具有交换性:type(a + b) is A 而 type(b + a) is B。
示例
__array_ufunc__ 图中的更长循环。
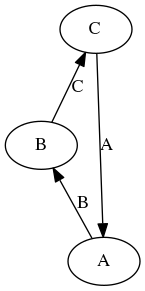
在这种情况下,__array_ufunc__ 关系存在一个更长的循环,并且类型转换层级不存在。二元操作仍然是可交换的,但类型传递性丢失:type(a + (b + c)) is A 但 type((a + b) + c) is C。
子类层级#
通常,将类层级映射到 Ufunc 类型转换层级是可取的。建议是,一个类的 __array_ufunc__ 实现通常应返回 NotImplemented,除非输入是相同类或超类的实例。这保证在类型转换层级中,超类在下方,子类在上方,而其他类不兼容。此规则的例外情况需要检查它们是否尊重隐式类型转换层级。
注意
请注意,类型转换层级和类层级在此处定义为“相反”方向。原则上,让 __array_ufunc__ 也处理子类的实例也是一致的。在这种情况下,“子类优先”的调度规则将确保相对相似的结果。然而,其行为的明确性会降低。
如果方法始终使用 super() 在类层级中传递,子类可以很容易地构建 [7]。为了支持这一点,ndarray 拥有自己的 __array_ufunc__ 方法,等同于:
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
# Cannot handle items that have __array_ufunc__ (other than our own).
outputs = kwargs.get('out', ())
objs = inputs + outputs
if "where" in kwargs:
objs = objs + (kwargs["where"], )
for item in objs:
if (hasattr(item, '__array_ufunc__') and
type(item).__array_ufunc__ is not ndarray.__array_ufunc__):
return NotImplemented
# If we didn't have to support legacy behaviour (__array_prepare__,
# __array_wrap__, etc.), we might here convert python floats,
# lists, etc, to arrays with
# items = [np.asarray(item) for item in inputs]
# and then start the right iterator for the given method.
# However, we do have to support legacy, so call back into the ufunc.
# Its arguments are now guaranteed not to have __array_ufunc__
# overrides, and it will do the coercion to array for us.
return getattr(ufunc, method)(*items, **kwargs)
请注意,作为一个特例,Ufunc 调度机制不会调用此 ndarray.__array_ufunc__ 方法,即使对于 ndarray 子类,如果它们未覆盖默认的 ndarray 实现。因此,调用 ndarray.__array_ufunc__ 不会导致嵌套的 Ufunc 调度循环。
使用 super() 对于 ndarray 的子类特别有用,这些子类只添加了一个像单位这样的属性。在它们的 __array_ufunc__ 实现中,这些类可以对其自身的类相关的参数进行可能的调整,然后使用 super() 将操作传递给超类实现,直到 Ufunc 实际完成,然后对输出进行可能的调整。
通常,__array_ufunc__ 的自定义实现应避免嵌套调度循环,即不仅通过 getattr(ufunc, method)(*items, **kwargs) 调用 Ufunc,还要捕获可能的异常等。当然,总会有例外。例如,对于像 MaskedArray 这样的类,它只关心其包含的任何内容都是 ndarray 子类,使用 __array_ufunc__ 进行重新实现可能更容易,只需直接将其 Ufunc 应用于其数据,然后调整掩码。实际上,这可以被视为类判断它是否可以处理其他参数(即它在类型层级中的位置)的一部分。在这种情况下,如果尝试失败,应该返回 NotImplemented。因此,实现将类似于:
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
# for simplicity, outputs are ignored here.
unmasked_items = tuple((item.data if isinstance(item, MaskedArray)
else item) for item in inputs)
try:
unmasked_result = getattr(ufunc, method)(*unmasked_items, **kwargs)
except TypeError:
return NotImplemented
# for simplicity, ignore that unmasked_result could be a tuple
# or a scalar.
if not isinstance(unmasked_result, np.ndarray):
return NotImplemented
# now combine masks and view as MaskedArray instance
...
举一个具体的例子,考虑一个“量”类(quantity class)和一个“掩码数组”类(masked array class),它们都重写了 __array_ufunc__,并有特定的实例 q 和 ma,其中 ma 包含一个普通数组。执行 np.multiply(q, ma) 时,ufunc 将首先调度到 q.__array_ufunc__,该方法返回 NotImplemented(因为“量”类将自身转换为数组并调用 super(),这会传递到 ndarray.__array_ufunc__,后者看到了 ma 上的覆盖)。接下来,ma.__array_ufunc__ 有机会执行。它不认识“量”类,如果它也只是返回 NotImplemented,则会引发 TypeError。但在我们的示例实现中,它使用 getattr(ufunc, method) 来有效地评估 np.multiply(q, ma.data)。这又会传递到 q.__array_ufunc__,但这次,由于 ma.data 是一个普通数组,它将返回一个也是“量”的结果。由于这是一个 ndarray 的子类,ma.__array_ufunc__ 可以将其转换为掩码数组,从而返回一个结果(显然,如果它不是数组子类,它仍然可以返回 NotImplemented)。
请注意,在上面讨论的类型层级上下文中,这是一个有点棘手的例子,因为 MaskedArray 有一个奇怪的位置:它高于 ndarray 的所有子类,因为它能够将它们转换为自己的类型,但它本身不知道如何与它们在 Ufunc 中进行交互。
关闭 Ufunc 功能#
对于某些类,Ufunc 没有意义,并且,就像其他一些特殊方法(如 __hash__ 和 __iter__ [8])一样,可以通过将 __array_ufunc__ 设置为 None 来指示 Ufunc 不可用。如果在任何将 __array_ufunc__ = None 的操作数上调用 Ufunc,它将无条件地引发 TypeError。
在类型转换层级中,这明确表明该类型相对于 ndarray 是不兼容的。
与 Python 二元操作结合时的行为#
Python 运算符在 ndarray 中的覆盖机制与 __array_ufunc__ 机制耦合。对于 Python 用于实现二元操作(如 * 和 +)的特殊方法调用,例如 ndarray.__mul__(self, other),NumPy 的 ndarray 实现以下行为:
如果
other.__array_ufunc__ is None,ndarray返回NotImplemented。控制权返回给 Python,Python 进而会尝试调用other上相应的反射方法(例如other.__rmul__),如果存在的话。如果
other上不存在__array_ufunc__属性,且other.__array_priority__ > self.__array_priority__,则ndarray也返回NotImplemented(且逻辑如前述情况所示)。这确保了与旧版 NumPy 的向后兼容性。否则,
ndarray将单方面调用相应的 Ufunc。Ufunc 绝不返回NotImplemented,因此,如果__array_ufunc__被设置为除None以外的任何值,则不能使用反射方法(如other.__rmul__)来覆盖 NumPy 数组的算术运算。相反,其行为需要通过实现与相应 Ufunc(例如np.multiply)一致的__array_ufunc__来改变。有关受影响的运算符及其相应 Ufunc 的列表,请参阅 运算符和 NumPy Ufunc 列表。
因此,希望修改与 ndarray 在二元操作中交互的类有两种选择:
实现
__array_ufunc__并遵循 NumPy 的 Python 二元操作语义(见下文)。设置
__array_ufunc__ = None,并自由实现 Python 二元操作。在这种情况下,对此参数调用的 Ufunc 将引发TypeError(参见 关闭 Ufunc 功能)。
实现二元操作的建议#
对于大多数数值类,覆盖二元操作最简单的方法是定义 __array_ufunc__ 并覆盖相应的 Ufunc。然后,该类可以像 ndarray 本身一样,根据 Ufunc 定义二元运算符。这里,需要注意确保允许其他类指示它们不兼容,即实现应该类似于:
def _disables_array_ufunc(obj):
try:
return obj.__array_ufunc__ is None
except AttributeError:
return False
class ArrayLike:
...
def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
...
return result
# Option 1: call ufunc directly
def __mul__(self, other):
if _disables_array_ufunc(other):
return NotImplemented
return np.multiply(self, other)
def __rmul__(self, other):
if _disables_array_ufunc(other):
return NotImplemented
return np.multiply(other, self)
def __imul__(self, other):
return np.multiply(self, other, out=(self,))
# Option 2: call into one's own __array_ufunc__
def __mul__(self, other):
return self.__array_ufunc__(np.multiply, '__call__', self, other)
def __rmul__(self, other):
return self.__array_ufunc__(np.multiply, '__call__', other, self)
def __imul__(self, other):
result = self.__array_ufunc__(np.multiply, '__call__', self, other,
out=(self,))
if result is NotImplemented:
raise TypeError(...)
为了理解为何需要谨慎,考虑另一个不知道如何处理数组和 Ufunc 的类 other,因此已将 __array_ufunc__ 设置为 None,但知道如何进行乘法:
class MyObject:
__array_ufunc__ = None
def __init__(self, value):
self.value = value
def __repr__(self):
return f"MyObject({self.value!r})"
def __mul__(self, other):
return MyObject(1234)
def __rmul__(self, other):
return MyObject(4321)
对于上述两种选项中的任何一种,我们都会得到预期结果:
mine = MyObject(0)
arr = ArrayLike([0])
mine * arr # -> MyObject(1234)
mine *= arr # -> MyObject(1234)
arr * mine # -> MyObject(4321)
arr *= mine # -> TypeError
这里,在第一个和第二个示例中,mine.__mul__(arr) 被调用,结果立即返回。在第三个示例中,首先调用 arr.__mul__(mine)。在选项 (1) 中,对 mine.__array_ufunc__ is None 的检查会成功,因此返回 NotImplemented,这导致执行 mine.__rmul__(arg)。在选项 (2) 中,大概是在 arr.__array_ufunc__ 内部明确了其他参数无法处理,同样返回 NotImplemented,从而将控制权传递给 mine.__rmul__。
对于第四个例子,即原位运算符,我们这里遵循了 ndarray 的做法,确保我们从不返回 NotImplemented,而是引发 TypeError。在选项 (1) 中,这间接发生:我们传递给 np.multiply,后者又立即引发 TypeError,因为其一个操作数 (out[0]) 禁止使用 Ufunc。在选项 (2) 中,我们直接传递给 arr.__array_ufunc__,它将返回 NotImplemented,我们会捕获它。
注意
不允许就地操作返回 NotImplemented 的原因在于,这些操作无法普遍地被简单的反向操作替代:大多数数组操作都假设实例的内容是就地更改的,而不期望生成新的实例。此外,ndarr[:] *= mine 会意味着什么?假设它意味着 ndarr[:] = ndarr[:] * mine,就像 Python 在 ndarr.__imul__ 返回 NotImplemented 时默认那样,这很可能是错误的。
现在考虑如果我们没有添加检查会发生什么。对于选项 (1),相关情况是如果我们没有检查 __array_func__ 是否设置为 None。在第三个示例中,arr.__mul__(mine) 被调用,如果没有检查,这会转到 np.multiply(arr, mine)。这会尝试 arr.__array_ufunc__,它返回 NotImplemented 并看到 mine.__array_ufunc__ is None,因此抛出 TypeError。
对于选项 (2),相关的例子是第四个,即 arr *= mine:如果我们让 NotImplemented 通过,Python 会将其替换为 arr = mine.__rmul__(arr),这不是我们想要的。
因为 Ufunc 覆盖和 Python 二元操作的语义几乎相同,所以在大多数情况下,选项 (1) 和 (2) 在相同的 __array_ufunc__ 实现下将产生相同的结果。一个例外是当第二个参数是第一个参数的子类时,尝试实现时的顺序,这是由于一个预计在 Python 3.7 中修复的 Python bug [9]。
总的来说,我们建议采用选项 (1),这是最接近 ndarray 本身所用选项的方法。请注意,选项 (1) 具有“病毒性”,这意味着任何希望支持与您的类进行二元操作的其他类现在也必须遵循这些规则,以支持与 ndarray 的二元算术(即,它们必须要么实现 __array_ufunc__,要么将其设置为 None)。我们认为这是一件好事,因为它确保了 Ufunc 和算术在所有支持它们的对象上的一致性。
为了简化此类类数组(array-like)的实现,混合类 NDArrayOperatorsMixin 为所有带有相应 Ufunc 的二元运算符提供了选项 (1) 风格的覆盖。希望为兼容版本的 NumPy 实现 __array_ufunc__,但同时也需要在旧版本上支持与 NumPy 数组的二元算术的类,应确保 __array_ufunc__ 也能用于实现它们支持的所有二元操作。
最后,我们注意到我们曾就让 MyObject 等类实现完整的 __array_ufunc__ 是否更有意义进行了广泛讨论 [6]。最终,我们更倾向于允许类选择退出,而上述推理使我们同意为 ndarray 本身采用类似的实现。选择退出机制要求禁用 Ufunc,这样类就不能定义 Ufunc 来返回与相应二元操作不同的结果(即,如果定义了 np.add(x, y),它应该与 x + y 匹配)。我们的目标是尽可能简化与 NumPy 数组的二元操作的调度逻辑,通过使它能够使用 Python 的调度规则或 NumPy 的调度规则,但不能同时混合使用两者。
运算符和 NumPy Ufunc 列表#
以下是 Python 二元运算符以及 ndarray 和 NDArrayOperatorsMixin 所使用的相应 NumPy Ufunc 的完整列表:
符号 |
运算符 |
NumPy Ufunc(s) |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NA |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
尚未作为 Ufunc 实现 [11] |
以下是一元运算符列表:
符号 |
运算符 |
NumPy Ufunc(s) |
|---|---|---|
|
|
|
|
|
|
NA |
|
|
|
|
|
未来对其他函数的扩展#
一些 NumPy 函数可以实现为(广义)Ufunc,在这种情况下,它们可以通过 __array_ufunc__ 方法进行覆盖。一个主要候选是 matmul(),它目前不是 Ufunc,但可以相对容易地重写为(一组)广义 Ufunc。同样的情况也可能发生在 median()、min() 和 argsort() 等函数上。