

NEP 40 — NumPy 中的传统数据类型实现#
- 标题:
NumPy 中的传统数据类型实现
- 作者:
Sebastian Berg
- 状态:
最终
- 类型:
信息性
- 创建时间:
2019-07-17
注意
此 NEP 是系列中的第一个
摘要#
作为 NumPy 增强提案 41、42 和 43 的准备,本 NEP 详细介绍了 NumPy 1.18 中 NumPy 数据类型的当前状态。它描述了一些促成其他提案的技术方面和概念。对于更一般的信息,大多数读者应首先阅读 NEP 41,并仅将本文档用作参考或获取额外详细信息。
详细描述#
本节描述了一些核心概念,并简要概述了当前 dtype 的实现以及讨论。在许多情况下,小节将大致分为首先描述当前实现,然后是“问题与讨论”部分。
参数化数据类型#
某些数据类型本质上是参数化的。所有 np.flexible 标量类型都附加到参数化数据类型(字符串、字节和 void)。标量类 np.flexible 是变长数据类型(字符串、字节和 void)的超类。这种区别同样通过 C 宏 PyDataType_ISFLEXIBLE 和 PyTypeNum_ISFLEXIBLE 暴露出来。这种灵活性推广到数组中可以表示的值集。例如,"S8" 可以表示比 "S4" 更长的字符串。因此,参数化字符串数据类型也限制了数组中的值是所有可以由字符串标量表示的值的子集(或子类型)。
基本的数值数据类型不灵活(不继承自 np.flexible)。float64、float32 等确实具有字节顺序,但描述的值不受其影响,并且始终可以将其转换为本地的规范表示形式而不会丢失任何信息。
灵活性的概念可以推广到参数化数据类型。例如,私有函数 PyArray_AdaptFlexibleDType 也接受朴素的 datetime dtype 作为输入以查找正确的时间单位。因此,datetime dtype 不是在其存储大小方面是参数化的,而是其存储值所代表的方面是参数化的。目前 np.can_cast("datetime64[s]", "datetime64[ms]", casting="safe") 返回 true,尽管尚不清楚这是否是期望的或是否可以推广到未来可能的数据类型,例如物理单位。
因此,我们有一些数据类型(主要是字符串)具有以下属性:
类型转换并非总是安全的(
np.can_cast("S8", "S4"))数组强制转换应该能够发现确切的 dtype,例如
np.array(["str1", 12.34], dtype="S"),其中 NumPy 发现结果 dtype 为"S5"。(如果省略 dtype 参数,行为目前是不明确的 [gh-15327]。) 类似于dtype="S"的形式是dtype="datetime64",它可以发现单位:np.array(["2017-02"], dtype="datetime64")。
这个概念强调了一些数据类型比基本数值数据类型更复杂,这在通用函数的复杂输出类型发现中显而易见。
基于值的类型转换#
类型转换通常定义在两种类型之间:当第二种类型可以表示第一种类型的所有值而不会丢失信息时,第一种类型被认为可以安全地转换为第二种类型。NumPy 可以检查实际值来决定类型转换是否安全。
这对于以下表达式很有用,例如
arr = np.array([1, 2, 3], dtype="int8")
result = arr + 5
assert result.dtype == np.dtype("int8")
# If the value is larger, the result will change however:
result = arr + 500
assert result.dtype == np.dtype("int16")
在此表达式中,Python 值(最初没有数据类型)被表示为 int8 或 int16(最小可能的数据类型)。
NumPy 目前甚至对 NumPy 标量和零维数组执行此操作,因此在上述表达式中将 5 替换为 np.int64(5) 或 np.array(5, dtype="int64") 将导致相同的结果,从而忽略现有数据类型。同样的逻辑也适用于浮点标量,它们允许丢失精度。当两个输入都是标量时,不使用此行为,因此 5 + np.int8(5) 返回默认整数大小(32 或 64 位)而不是 np.int8。
虽然此行为是根据类型转换定义的,并通过 np.result_type 暴露,但它主要对通用函数(如上述示例中的 np.add)很重要。通用函数目前依赖于安全类型转换语义来决定应该使用哪个循环,从而决定输出数据类型。
问题与讨论#
似乎对于具有数据类型的值,当前方法并不可取,但对于第一个示例中的纯 Python 整数或浮点数可能很有用。然而,数据类型系统和通用函数调度中的任何更改都必须最初完全支持当前行为。一个主要困难是,例如,值 156 可以由 np.uint8 和 np.int16 表示。结果取决于转换上下文中的“最小”表示(对于 ufuncs,上下文可能取决于循环顺序)。
对象数据类型#
对象数据类型目前作为任何无法以其他方式表示的值的通用回退。然而,由于没有明确定义的类型,它存在一些问题,例如当数组填充 Python 序列时
>>> l = [1, [2]]
>>> np.array(l, dtype=np.object_)
array([1, list([2])], dtype=object) # a 1d array
>>> a = np.empty((), dtype=np.object_)
>>> a[...] = l
ValueError: assignment to 0-d array # ???
>>> a[()] = l
>>> a
array(list([1, [2]]), dtype=object)
如果没有明确定义的类型,诸如 isnan() 或 conjugate() 之类的函数不一定能工作,但对于 decimal.Decimal 可能可以工作。为了改善这种情况,似乎有必要使其易于创建代表特定 Python 数据类型并将其对象以指向 Python PyObject 的指针形式存储在数组中的 object dtypes。与大多数数据类型不同,Python 对象需要垃圾回收。这意味着必须定义处理引用和访问所有对象的附加方法。实际上,对于大多数用例,限制此类数据类型的创建就足够了,以便所有与 Python C 级别引用相关的功能都是 NumPy 私有的。
创建与内置 Python 对象匹配的 NumPy 数据类型也带来了一些需要更多思考和讨论的问题。这些问题无需立即解决
NumPy 目前在某些情况下甚至对数组输入也返回标量,在大多数情况下,这可以无缝工作。然而,这仅仅是因为 NumPy 标量的行为与 NumPy 数组非常相似,而一般 Python 对象不具备此功能。
无缝集成可能要求
np.array(scalar)自动找到正确的 DType,因为某些操作(如索引)返回标量而不是 0D 数组。如果多个用户独立决定实现例如decimal.Decimal的 DType,这将产生问题。
当前 dtype 实现#
目前 np.dtype 是一个 Python 类,其实例是 np.dtype(">float64") 等实例。为了设置这些实例的实际行为,一个原型实例被全局存储,并根据 dtype.typenum 进行查找。单例在可能的情况下被使用。在需要时,它会被复制和修改,例如为了改变字节序。
参数化数据类型(字符串、void、datetime 和 timedelta)必须存储额外的信息,例如字符串长度、字段或 datetime 单位——这些类型的新实例会被创建,而不是依赖于单例。NumPy 中所有当前的数据类型在创建过程中进一步支持设置一个元数据字段,该字段可以设置为任意字典值,但在实践中很少使用(一个最近且突出的用户是 h5py)。
许多数据类型特有的函数定义在一个名为 PyArray_ArrFuncs 的 C 结构中,该结构是每个 dtype 实例的一部分,与 Python 的 PyNumberMethods 有相似之处。对于用户定义的数据类型,此结构暴露给用户,使得 ABI 兼容的更改无法实现。此结构包含重要信息,例如如何复制或转换,并为函数指针提供空间,例如比较元素、转换为布尔值或排序。由于其中一些函数是向量化操作,对多个元素进行操作,它们符合 ufuncs 的模型,并且将来无需在数据类型上定义。例如,np.clip 函数以前使用 PyArray_ArrFuncs 实现,现在已作为 ufunc 实现。
讨论和问题#
当前 dtype 上函数的另一个问题是,与方法不同,它们在调用时不会传入 dtype 实例。相反,在许多情况下,传入的是正在操作的数组,并且通常仅用于再次提取数据类型。未来的 API 可能应该停止传入完整的数组对象。由于需要回退到旧定义以实现向后兼容性,因此数组对象可能不可用。但是,传入一个主要定义了数据类型的“假”数组可能是一个足够的权宜之计(参见向后兼容性;有时也可能需要对齐信息)。
尽管在 NumPy 本身之外没有广泛使用,但当前的 PyArray_Descr 是一个公共结构。对于存储在 f 字段中的 PyArray_ArrFuncs 结构尤其如此。由于兼容性,它们可能需要长时间保持支持,并有可能被调度到新 API 的函数所取代。
然而,从长远来看,对这些结构的访问可能不得不被弃用。
NumPy 标量和类型层次结构#
作为上述数据类型实现的附注:与数据类型不同,NumPy 标量目前**确实**提供了一个类型层次结构,由诸如 np.inexact 等抽象类型组成(见下图)。事实上,NumPy 中有些控制流目前使用 issubclass(a.dtype.type, np.inexact)。
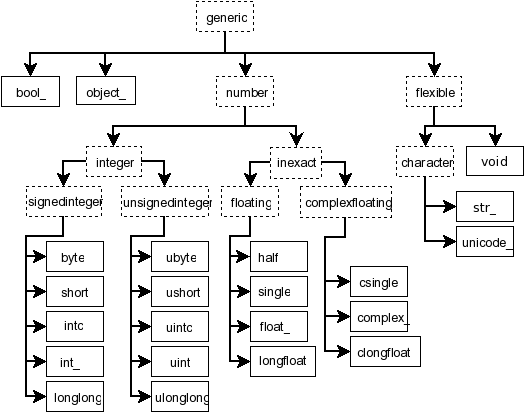
图: 从参考文档中复制的 NumPy 标量类型层次结构。排除了一些别名,例如 np.intp。未显示 Datetime 和 timedelta。#
NumPy 标量尝试模仿具有固定数据类型的零维数组。对于数值(和 unicode)数据类型,它们进一步限制为本地字节序。
当前类型转换实现#
数据类型需要支持的主要功能之一是使用 arr.astype(new_dtype, casting="unsafe") 或在执行具有不同类型的 ufuncs(例如添加整数和浮点数)期间相互转换。
类型转换表确定是否可以将一种特定类型转换为另一种。然而,通用类型转换规则无法处理参数化 dtype,例如字符串。参数化数据类型的逻辑主要在 PyArray_CanCastTo 中定义,目前无法为用户定义的数据类型自定义。
实际的类型转换有两个不同的部分
copyswap/copyswapn为每种 dtype 定义,可以处理非本机字节顺序的字节交换以及未对齐的内存。通用类型转换代码由 C 函数提供,这些函数知道如何将对齐和连续的内存从一种 dtype 转换为另一种 dtype(两者都采用本机字节序)。这些 C 级函数可以注册以将对齐和连续的内存从一种 dtype 转换为另一种。该函数可以提供两个数组(尽管对于标量,参数有时为
NULL)。NumPy 将确保这些函数接收本机字节序输入。当前实现将函数存储在被类型转换的数据类型上的 C 数组中,或者在类型转换为用户定义数据类型时存储在字典中。
通常 NumPy 会执行由 in_copyswapn -> castfunc -> out_copyswapn 三个函数组成的链式转换,并在这些步骤之间使用(小)缓冲区。
上述多个函数被封装到一个单一函数(带有元数据)中,该函数处理类型转换,例如在 ufuncs 使用的缓冲迭代期间使用。这是用户定义数据类型始终使用的机制。对于 NumPy 本身内部定义的大多数 dtypes,使用更专门的代码来查找执行实际类型转换的函数(由私有 PyArray_GetDTypeTransferFunction 定义)。此机制取代了上述大部分机制,并为例如当输入在内存中不连续时提供更快的类型转换。然而,它不能通过用户定义的数据类型进行扩展。
与类型转换相关,我们目前有一个 PyArray_EquivTypes 函数,它指示一个视图是否足够(因此不需要类型转换)。此函数在多个地方使用,并且可能应该成为重新设计的类型转换 API 的一部分。
通用函数中的 DType 处理#
通用函数以 numpy.UFunc 类的实例形式实现,其中包含一个按顺序排列的(基于 dtype 类型码字符,而不是 dtype 实例的)特定数据类型实现列表,每个实现都有一个签名和一个函数指针。这个实现列表可以通过 ufunc.types 查看,所有实现都以其 C 风格的类型码签名列出。例如:
>>> np.add.types
[...,
'll->l',
...,
'dd->d',
...]
这些签名中的每一个都与 C 中定义的单个内部循环函数相关联,该函数执行实际计算,并且可以被多次调用。
寻找正确内部循环函数的主要步骤是调用 PyUFunc_TypeResolutionFunc,它从提供的输入数组中检索输入 dtypes,并确定要执行的完整类型签名(包括输出 dtype)。
默认情况下,TypeResolver 的实现是通过按顺序搜索 ufunc.types 中列出的所有实现,并在所有输入都可以安全地转换以适应签名时停止。这意味着如果添加长整型(l)和双精度浮点型(d)数组,NumPy 将发现 'dd->d' 定义有效(长整型可以安全地转换为双精度浮点型),并使用该定义。
在某些情况下,这并不可取。例如,np.isnat 通用函数有一个 TypeResolver,它拒绝整数输入而不是允许它们转换为浮点数。原则上,下游项目目前可以使用自己的非默认 TypeResolver,因为实现此目的所需的相应 C 结构是公共的。已知唯一这样做的是 Astropy,如果 NumPy 删除替换 TypeResolver 的可能性,它愿意切换到新的 API。
对于用户定义的数据类型,调度逻辑是相似的,尽管是单独实现且受限的(参见下面的讨论)。
问题与讨论#
目前,只有当任何输入(或输出)具有用户数据类型时,才能找到/解析用户定义的函数,因为它使用 OO->O 签名。例如,假设已经实现了用于实现 fraction_divide(int, int) -> Fraction 的 ufunc 循环,那么调用 fraction_divide(4, 5)(没有特定的输出 dtype)将失败,因为包含用户数据类型 Fraction(作为输出)的循环只有在任何输入已经是 Fraction 时才能找到。fraction_divide(4, 5, dtype=Fraction) 可以使其工作,但这很不方便。
通常,调度是通过寻找第一个匹配的循环来完成的。匹配的定义是:所有输入(和可能的输出)都可以安全地转换为签名类型字符(另请参阅当前实现部分)。但是,在某些情况下,安全转换存在问题,因此明确不允许。例如,np.isnat 函数目前仅对 datetime 和 timedelta 定义,即使整数被定义为可以安全地转换为 timedelta。如果不是这样,调用 np.isnat(np.array("NaT", "timedelta64").astype("int64")) 目前将返回 true,尽管整数输入数组没有“不是时间”的概念。如果一个通用函数,例如 scipy.special 中的大多数函数,只定义了 float32 和 float64,它将自动将 float16 静默转换为 float32(对于任何整数输入也类似)。这确保了成功执行,但在向 ufunc 添加新数据类型的支持时,可能会导致输出 dtype 发生变化。当添加 float16 循环时,输出数据类型目前将从 float32 更改为 float16,而不会发出警告。
通常,循环注册的顺序很重要。但是,只有在首次定义 ufunc 时添加所有循环,这才是可靠的。导入新的用户数据类型时添加的其他循环不得对导入发生的顺序敏感。
有两种主要方法可以更好地定义用户定义类型的类型解析:
允许用户 dtypes 直接影响循环选择。例如,它们可以提供一个函数,当没有精确匹配的循环可用时,该函数返回/选择一个循环。
定义所有实现/循环的完整排序,可能基于“安全转换”语义或类似的语义。
虽然选项 2 可能更容易理解,但它是否足以满足所有(或大多数)用例仍有待观察。
UFuncs 中参数化输出 DType 的调整#
参数化 dtypes 所需的第二步目前在 TypeResolver 中执行:datetime 和 timedelta 数据类型必须决定操作和输出数组的正确参数。此步骤还需要仔细检查所有类型转换是否可以安全执行,这在默认情况下意味着它们是“相同种类”的类型转换。
问题与讨论#
修正正确的输出 dtype 目前是类型解析的一部分。然而,它是一个独立的步骤,在实际类型/循环解析发生后,应该对其进行相应的处理。
因此,此步骤可能从调度步骤(如上所述)转移到下面描述的特定于实现的_代码_。
UFunc 的 DType 特定实现#
一旦找到正确的实现/循环,UFuncs 目前会调用一个用 C 编写的内部循环函数。这可能会被多次调用以完成完整的计算,并且它对当前上下文的信息很少或没有。它也没有返回值。
问题与讨论#
参数化数据类型可能需要将额外信息传递给内部循环函数,以决定如何解释数据。这就是目前 string dtypes 没有通用函数的原因(尽管在 NumPy 本身内部技术上是可能的)。请注意,目前可以传入输入数组对象(当不需要类型转换时,这些对象反过来又持有数据类型)。然而,完整的数组信息不应该被要求,并且目前在任何类型转换发生之前传入数组。此功能在 NumPy 内部未使用,并且不存在已知的用户。
另一个问题是内部循环函数中的错误报告。目前有两种方法可以做到这一点:
通过设置 Python 异常
使用 CPU 浮点错误标志。
这两种方式都在返回给用户之前进行检查。然而,许多整数函数目前不能设置这些错误中的任何一个,因此检查浮点错误标志是不必要的开销。另一方面,目前没有办法停止迭代或传递错误信息,而不使用浮点标志或需要持有 Python 全局解释器锁(GIL)。
似乎有必要为内部循环函数的作者提供更多控制权。这意味着允许用户更轻松地将信息传入和传出内部循环函数,同时不提供输入数组对象。最有可能这将涉及:
允许在第一次和最后一次内部循环调用之前和之后执行额外的代码。
从内部循环返回一个整数值,以允许提前停止迭代并可能传播错误信息。
可能,允许专门的内部循环选择。例如,目前
matmul和许多归约将对某些输入执行优化代码。允许事先选择这些优化循环可能是有意义的。允许这样做也可能有助于使类型转换(大量使用此功能)和 ufunc 实现更接近。
围绕内部循环函数的问题已在 GitHub issue gh-12518 中进行了详细讨论。
规约操作使用一个“标识”值。这目前是每个 ufunc 定义一次的,无论 ufunc dtype 签名是什么。例如,0 用于 sum,或 math.inf 用于 min。这对于数值数据类型很有效,但并不总是适用于其他 dtypes。通常,应该能够为 ufunc 规约提供 dtype 特定的标识。
数组强制转换期间的数据类型发现#
调用 np.array(...) 将通用 Python 对象强制转换为 NumPy 数组时,需要检查所有对象以找到正确的 dtype。 np.array() 的输入可能是嵌套的 Python 序列,它们将最终元素作为通用 Python 对象持有。NumPy 必须解包所有嵌套序列,然后检查元素。最终数据类型是通过遍历数组中所有元素并执行以下操作找到的:
发现单个元素的 dtype
从数组(或类似数组)或 NumPy 标量使用
element.dtype对于已知的 Python 类型,使用
isinstance(..., float)(请注意,这些规则意味着子类目前是有效的)。用于强制转换元组的 void 数据类型的特殊规则。
使用
np.promote_types提升当前 dtype 与下一个元素的 dtype。如果找到字符串,整个过程将重新开始(另请参见 [gh-15327]),方式类似于给出
dtype="S"时(参见下文)。
如果给定了 dtype=...,则此 dtype 将不加修改地使用,除非它是一个不具体的参数化 dtype 实例,这意味着“S0”、“V0”、“U0”、“datetime64”和“timedelta64”。因此,它们是长度为 0 的灵活数据类型——被认为是无大小的——以及没有附加单位的日期时间或时间差(“通用单位”)。
在未来的 DType 类层次结构中,这些可能由类而不是特殊实例表示,因为这些特殊实例通常不应附加到数组。
如果提供了此类参数化 dtype 实例,例如使用 dtype="S",则会调用 PyArray_AdaptFlexibleDType,并有效地使用 DType 特定逻辑检查所有值。也就是说:
字符串将使用
str(element)来查找大多数元素的长度Datetime64 能够从字符串进行强制转换并猜测正确的单位。
讨论和问题#
在正常发现过程中,isinstance 似乎更应该严格地进行 type(element) is desired_type 检查。此外,当前的 AdaptFlexibleDType 逻辑应该提供给用户 DType,而不是作为次要步骤,而是取代或成为正常发现的一部分。
讨论#
关于当前状态和未来数据类型系统可能是什么样子,已经进行了许多讨论。这些讨论的完整列表很长,有些已经随着时间流逝而丢失,以下提供了一些最近讨论的子集:
Stephan Hoyer 在一次开发者会议后起草的 NEP(在下一次开发者会议上更新)https://hackmd.io/6YmDt_PgSVORRNRxHyPaNQ
先前在此处收集的相关文档列表 https://hackmd.io/UVOtgj1wRZSsoNQCjkhq1g (TODO: 精简至最重要的部分)
numpy/numpy#12630 Matti Picus 起草的 NEP,更多地从
ArrFunctions的角度讨论了子类化的技术方面https://hackmd.io/ok21UoAQQmOtSVk6keaJhw 和 https://hackmd.io/s/ryTFaOPHE (2019-04-30) 子类化实现方法的提案。
关于 ufuncs 调用约定以及对更强大 UFuncs 需求的讨论: numpy/numpy#12518
2018-11-30 开发者会议纪要:BIDS-numpy/docs 及后续 NEP 草案:https://hackmd.io/6YmDt_PgSVORRNRxHyPaNQ
2018年11月30日 BIDS 会议和 Stephan Hoyer 关于 NumPy 应提供什么以及如何实现的想法的文档。与 Eric Wieser、Matti Picus、Charles Harris、Tyler Reddy、Stéfan van der Walt 和 Travis Oliphant 的会议。
SciPy 2018 头脑风暴会议,附有用例总结:numpy/numpy
还列出了一些需求和实现思路
参考文献#
版权#
本文档已置于公共领域。