numpy.ma.polyfit#
- ma.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)[source]#
最小二乘多项式拟合。
注意
这属于旧的多项式 API 的一部分。从 1.4 版本开始,推荐使用
numpy.polynomial中定义的新多项式 API。有关差异的总结,请参见 过渡指南。将度数为 deg 的多项式
p(x) = p[0] * x**deg + ... + p[deg]拟合到点 (x, y)。返回系数向量 p,该向量以 deg、deg-1、… 0 的顺序最小化平方误差。对于新代码,建议使用
Polynomial.fit类方法,因为它在数值上更稳定。有关更多信息,请参阅该方法的文档。- 参数:
- xarray_like,形状 (M,)
M 个样本点
(x[i], y[i])的 x 坐标。- yarray_like,形状 (M,) 或 (M, K)
样本点的 y 坐标。通过传递包含每个数据集一列的二维数组,可以一次拟合多个共享相同 x 坐标的样本点数据集。
- degint
拟合多项式的次数
- rcondfloat,可选
拟合的相对条件数。小于此值相对于最大奇异值的奇异值将被忽略。默认值为 len(x)*eps,其中 eps 是浮点类型的相对精度,在大多数情况下约为 2e-16。
- fullbool,可选
确定返回值性质的开关。当它为 False(默认值)时,仅返回系数,当它为 True 时,还会返回来自奇异值分解的诊断信息。
- warray_like,形状 (M,),可选
权重。如果非 None,则权重
w[i]应用于在x[i]处的未平方残差y[i] - y_hat[i]。理想情况下,权重的选择应使乘积w[i]*y[i]的误差都具有相同的方差。当使用逆方差加权时,使用w[i] = 1/sigma(y[i])。默认值为 None。- covbool 或 str,可选
如果给出且不为 False,则不仅返回估计值,还返回其协方差矩阵。默认情况下,协方差按 chi2/dof 进行缩放,其中 dof = M - (deg + 1),即,假设权重不可靠,除非在相对意义上,并且所有内容都按比例缩放,以便约化 chi2 为 1。如果
cov='unscaled',则省略此缩放,这与权重为 w = 1/sigma 的情况相关,其中已知 sigma 是不确定度的可靠估计。
- 返回值:
- pndarray,形状 (deg + 1,) 或 (deg + 1, K)
多项式系数,最高次幂在前。如果 y 是二维数组,则第 k 个数据集的系数位于
p[:,k]中。- 残差、秩、奇异值、rcond
仅当
full == True时才会返回这些值。residuals – 最小二乘拟合的残差平方和
- rank – 缩放后的范德蒙德矩阵的有效秩
系数矩阵
- singular_values – 缩放后的范德蒙德矩阵的奇异值
系数矩阵
rcond – rcond 的值。
更多详细信息,请参见
numpy.linalg.lstsq。- Vndarray,形状 (deg + 1, deg + 1) 或 (deg + 1, deg + 1, K)
仅当
full == False且cov == True时存在。多项式系数估计的协方差矩阵。该矩阵的对角线是每个系数的方差估计。如果 y 是二维数组,则第 k 个数据集的协方差矩阵位于V[:,:,k]中。
- 警告:
- RankWarning
最小二乘拟合中系数矩阵的秩不足。仅当
full == False时才会发出警告。可以通过以下方式关闭警告:
>>> import warnings >>> warnings.simplefilter('ignore', np.exceptions.RankWarning)
另请参阅
polyval计算多项式值。
linalg.lstsq计算最小二乘拟合。
scipy.interpolate.UnivariateSpline计算样条拟合。
注释
x 中的任何掩码值都会传播到 y 中,反之亦然。
该解决方案最小化平方误差
\[E = \sum_{j=0}^k |p(x_j) - y_j|^2\]在以下方程式中
x[0]**n * p[0] + ... + x[0] * p[n-1] + p[n] = y[0] x[1]**n * p[0] + ... + x[1] * p[n-1] + p[n] = y[1] ... x[k]**n * p[0] + ... + x[k] * p[n-1] + p[n] = y[k]
系数 p 的系数矩阵是范德蒙德矩阵。
polyfit当最小二乘拟合条件很差时,会发出RankWarning。这意味着由于数值误差,最佳拟合没有得到很好的定义。可以通过降低多项式次数或用 x - x.mean() 替换 x 来改进结果。rcond 参数也可以设置为小于其默认值的值,但由此产生的拟合可能是虚假的:包含来自小奇异值的影响会为结果添加数值噪声。请注意,当多项式的次数很大或样本点的区间中心位置不佳时,拟合多项式系数本质上是条件很差的。在这些情况下,应始终检查拟合的质量。当多项式拟合不令人满意时,样条可能是不错的替代方案。
参考文献
[1]维基百科,“曲线拟合”,https://en.wikipedia.org/wiki/Curve_fitting
[2]维基百科,“多项式插值”,https://en.wikipedia.org/wiki/Polynomial_interpolation
示例
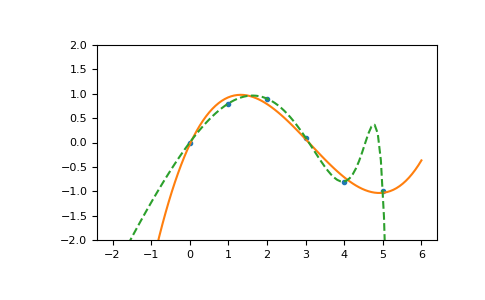
>>> import numpy as np >>> import warnings >>> x = np.array([0.0, 1.0, 2.0, 3.0, 4.0, 5.0]) >>> y = np.array([0.0, 0.8, 0.9, 0.1, -0.8, -1.0]) >>> z = np.polyfit(x, y, 3) >>> z array([ 0.08703704, -0.81349206, 1.69312169, -0.03968254]) # may vary
使用
poly1d对象处理多项式很方便。>>> p = np.poly1d(z) >>> p(0.5) 0.6143849206349179 # may vary >>> p(3.5) -0.34732142857143039 # may vary >>> p(10) 22.579365079365115 # may vary
高阶多项式可能会剧烈振荡。
>>> with warnings.catch_warnings(): ... warnings.simplefilter('ignore', np.exceptions.RankWarning) ... p30 = np.poly1d(np.polyfit(x, y, 30)) ... >>> p30(4) -0.80000000000000204 # may vary >>> p30(5) -0.99999999999999445 # may vary >>> p30(4.5) -0.10547061179440398 # may vary
插图
>>> import matplotlib.pyplot as plt >>> xp = np.linspace(-2, 6, 100) >>> _ = plt.plot(x, y, '.', xp, p(xp), '-', xp, p30(xp), '--') >>> plt.ylim(-2,2) (-2, 2) >>> plt.show()